半监督学习 推荐 https://www.huaxiaozhuan.com/统计学习/chapters/12_semi_supervised.html ,太强了,太强了
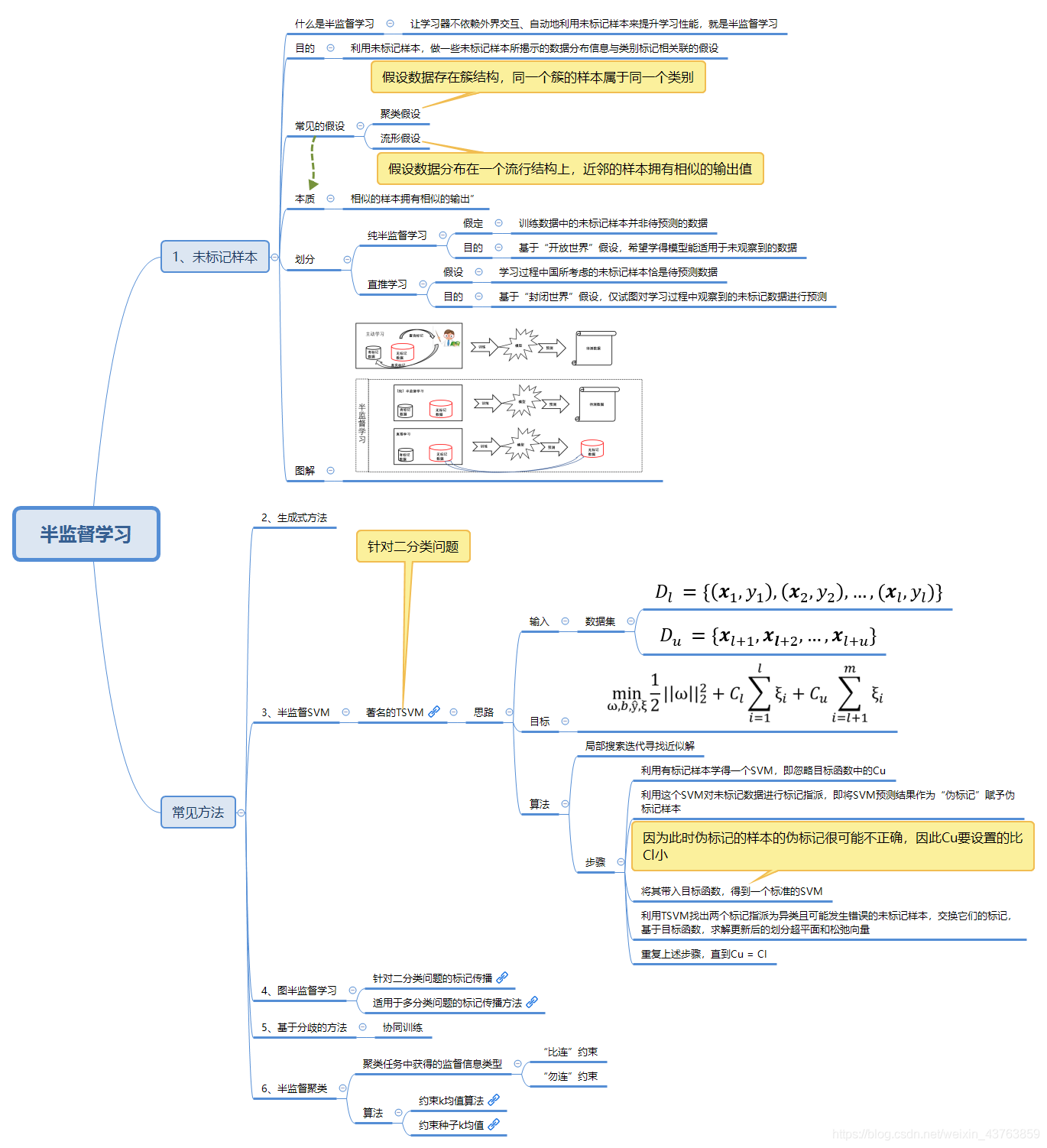
啥是半监督学习(Semi-supervised Learning) 让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能,就是半监督学习,现实生活中,我们很容易收集无标签数据,但有标签数据并不容易收集,所以我们需要一种模型,以少量标签数据作为参照,利用大量无标签数据进行训练,得到一个更高效的学习器。
也可以这样理解,半监督学习就是监督学习和无监督学习的折中版,而监督学习的核心就是回归,无监督学习的核心是分类,半监督学习一般的目标是找到一个函数迎合(也就是回归任务),然后用分类任务的信息去优化回归函数。
给定有标记样本集合 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} D u = { ( x ⃗ l + 1 , y l + 1 ) , ( x ⃗ l + 2 , y l + 2 ) , ⋯ , ( x ⃗ l + u , y l + u ) } \mathbb D_u=\{(\mathbf{\vec x}_{l+1},y_{l+1}),(\mathbf{\vec x}_{l+2},y_{l+2}),\cdots,(\mathbf{\vec x}_{l+u},y_{l+u})\} D u = {( x l + 1 , y l + 1 ) , ( x l + 2 , y l + 2 ) , ⋯ , ( x l + u , y l + u )} l ≪ u l \ll u l ≪ u
学习器自动地利用未标记的 D u \mathbb D_u D u semi-supervised learning。
半监督学习的现实需求非常强烈,因为现实中往往能够容易地收集到大量未标记样本,但是对其标记需要耗费大量的人力、物力。如:在医学影像分析上,对影像的疾病标记需要专家人工进行。
因此可以通过专家人工标注少量的样本,然后采用半监督学习。
虽然未标记样本集 D u \mathbb D_u D u D u \mathbb D_u D u D l \mathbb D_l D l D u \mathbb D_u D u
要利用未标记样本,必然需要对未标记样本的分布与已标记样本的分布的关联做出假设。
最常见的假设是聚类假设cluster assumption:假设数据存在簇结构,同一个簇的样本属于同一个类别。 另一种常见假设是流形假设manifold assumption:假设数据分布在一个流形结构上,邻近的样本拥有相似的输出值。其中,邻近的程度用相似度来刻画。 流形假设可以看作是聚类假设的推广,但流形假设对于输出值没有限制(可以为类别,也可以为实数),因此比聚类假设的适用程度更广,可用于多类型的学习任务。 无论聚类假设还是流形假设,本质都假设是:相似的样本有相似的输出 。 半监督学习可以划分为:纯pure半监督学习和直推学习transduction learning 。
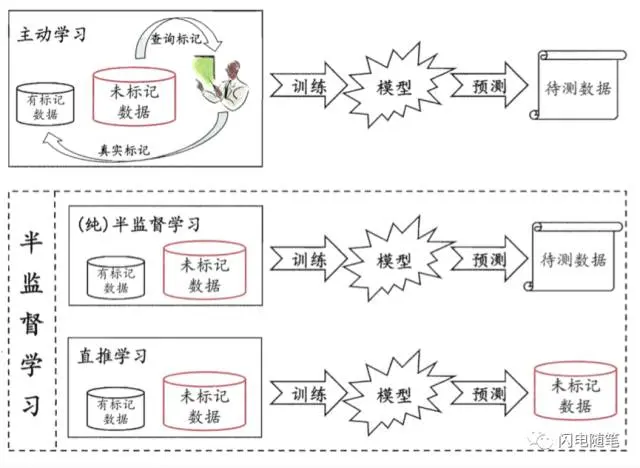
纯半监督学习:假定训练数据中的未标记样本集 D u \mathbb D_u D u
纯半监督学习是开放性的,它学得的模型能够适用于额外的未观测数据。
直推学习:假定学习过程中考虑的未标记样本集 D u \mathbb D_u D u D u \mathbb D_u D u
直推学习是封闭性的,它学得的模型仅仅是针对学习过程中的未标记样本集 D u \mathbb D_u D u
一般,半监督学习算法可分为:self-training(自训练算法)、Graph-based Semi-supervised Learning(基于图的半监督算法)、Semi-supervised supported vector machine(半监督支持向量机,S3VM)。简单介绍如下:
1.简单自训练 (simple self-training):用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,这样就会产生伪标签(pseudo label)或软标签(soft label),挑选你认为分类正确的无标签样本(此处应该有一个挑选准则 ),把选出来的无标签样本用来训练分类器。
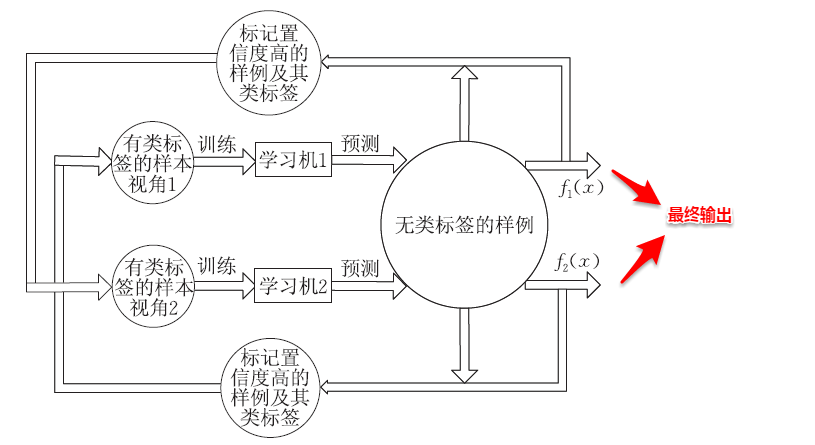
2.协同训练 (co-training):其实也是 self-training 的一种,但其思想是好的。假设每个数据可以从不同的角度(view)进行分类,不同角度可以训练出不同的分类器,然后用这些从不同角度训练出来的分类器对无标签样本进行分类,再选出认为可信的无标签样本加入训练集中。由于这些分类器从不同角度训练出来的,可以形成一种互补,而提高分类精度;就如同从不同角度可以更好地理解事物一样。
3.半监督字典学习 :其实也是 self-training 的一种,先是用有标签数据作为字典,对无标签数据进行分类,挑选出你认为分类正确的无标签样本,加入字典中(此时的字典就变成了半监督字典了)
4.标签传播算法 (Label Propagation Algorithm):是一种基于图的半监督算法,通过构造图结构(数据点为顶点,点之间的相似性为边)来寻找训练数据 中有标签数据和无标签数据的关系。是的,只是训练数据中,这是一种直推式的半监督算法,即只对训练集中的无标签数据进行分类,这其实感觉很像一个有监督分类算法…,但其实并不是,因为其标签传播的过程,会流经无标签数据,即有些无标签数据的标签的信息,是从另一些无标签数据中流过来的,这就用到了无标签数据之间的联系
5.半监督支持向量机 :监督支持向量机是利用了结构风险最小化来分类的,半监督支持向量机还用上了无标签数据的空间分布信息,即决策超平面应该与无标签数据的分布一致(应该经过无标签数据密度低的地方)(这其实是一种假设 ,不满足的话这种无标签数据的空间分布信息会误导决策超平面,导致性能比只用有标签数据时还差)
半监督学习的方法大都建立在对数据的某种假设 上,只有满足这些假设,半监督算法才能有性能的保证,这也是限制了半监督学习应用的一大障碍。
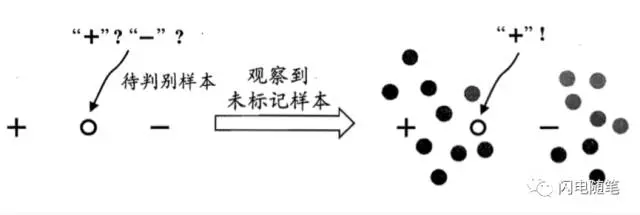
事实上,未标记样本虽未直接包含标记信息,但若他们与有标记样本是从同样的数据源独立同分布采样而来,则它们所包含的关于数据分布的信息对建立模型将大有裨益。
下图给出了一个直观的示例。若仅基于图中的一个正例和反例,则由于待判别样本恰位于两者正中间,大体上只能随机猜测;若能观察到图中的为标记样本,则将很有把握的判别为正例。
让学习器不依赖外界交互、自动地利用为标记样本来提升学习性能,就是半监督学习(semi-supervised learning)。
半监督学习还可细分为纯(pure)半监督学习和直推学习,前者假定训练数据中的为标记数据并非待预测数据,而后者则假定学习过程中所考虑的为标记样本恰是待预测数据。下图直观的显示出主动学习、纯监督学习和直推学习的区别。
半监督学习要利用未标记样本,必然要做一些将未标记样本所揭示的数据分布信息与类别标记想联系的假设,其本质是 “相似的样本拥有相似的输出”
半监督学习的假定 平滑性假定 如果两个点在高密度区域中(数据分布的概率密度比较大),且这两个点距离很近,那么他们的输出也会十分的接近。
聚类假定 即假设数据存在簇结构, 同一个簇的样本属于同一个类别,也就是说,如果两个点在相同的聚类中,那么他们趋向于被分成同一类。
流形假定 即假设数据分布在一个流形结构上, 邻近的样本拥有相似的输出值.
高维的数据一般都会处于一个低维的流形中。那么问题来了,这个流形是什么呢?
流形是局部具有欧几里得空间性质的空间,在数学中用于描述几何形体。用更简单的实例表述,就是:
假设一个三维空间 R3,那么在这个三维空间的低维分布,或者说低维嵌入,比如曲面函数 z 2 = x 2 + y 2 z^2=x^2+y^2 z 2 = x 2 + y 2 x = e − 0.1 ∗ z ∗ c o s ( z ) x=e^{-0.1*z}*cos(z) x = e − 0.1 ∗ z ∗ cos ( z ) x = e − 0.1 ∗ z ∗ s i n ( z ) x=e^{-0.1*z} *sin(z) x = e − 0.1 ∗ z ∗ s in ( z )
以此类推,高维空间中的低维分布就是我理解中的流形。
“邻近”程度常用 “相似” 程度来刻画, 因此, 流形假设可看作聚类假设的推广, 但流形假设对输出值没有限制 , 因此比聚类假设的适用范围更广, 可用于更多类型的学习任务, 事实上, 无论聚类假设还是流形假设, 其本质都是 “相似的样本拥有相似的输出 ” 这个基本假设.
引自李宏毅深度学习笔记
假设现在做分类任务,建一个猫和狗的分类器。有一大堆猫和狗的图片,这些图片没有 label。
假设只考虑有 label 的猫和狗图片,要画一个边界,把猫和狗训练数据集分开,可能会画一条如上图所示的红色竖线。假如未标注数据的分布如上图灰色点,可能会影响你的决定。未标注数据虽然只告诉我们 input,但它们的分布可以告诉我们一些信息。
比如加入灰色点后,你会把边界画成红色斜线。
半监督学习使用未标注数据的方式,往往伴随着一些假设,所以有没有用取决于假设符不符合实际。你可能觉得左下的灰点是猫,但是可能是狗,因为两张图片的背景看起来很像。
生成式方法 生成式generative methods 半监督学习方法:直接基于生成式模型的方法。
生成式半监督学习方法假设所有数据(无论是否有标记),都是由同一个潜在的模型生成的。
该假设使得能够通过潜在模型的参数将未标记样本与学习目标联系起来。 未标记样本的标记可以视作模型的缺失参数,通常可以基于EM算法进行极大似然估计求解。 生成式半监督学习方法其实是一个算法框架,内部不同算法的主要区别在于生成式模型的假设:不同的假设将产生不同的方法。
通常可基于 EM 算法进行极大似然估计求解。EM(Expectation Maximization)算法也叫期望最大化算法,在西瓜书第七章有过介绍。该算法的核心思想是通过 E 步来对未知变量进行估算,然后通过估算出来的变量在 M 步使用极大似然估计法(在第七章也有介绍)对模型参数进行估算。在反复迭代 E, M 步骤的过程中使预估的参数收敛到局部最优解。
生成式高斯混合半监督学习算法 给定样本 x ⃗ \mathbf{\vec x} x y ∈ Y = { 1 , 2 , ⋯ , K } y \in \mathcal Y=\{1,2,\cdots,K\} y ∈ Y = { 1 , 2 , ⋯ , K }
假设样本由高斯混合模型产生,且每个类别对应一个高斯混合成分。即数据样本是基于概率密度:
p ( x ⃗ ) = ∑ k = 1 K α k p k ( x ⃗ ; μ ⃗ k , Σ k ) p(\mathbf{\vec x})=\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k) p ( x ) = k = 1 ∑ K α k p k ( x ; μ k , Σ k )
来产生的。其中:
p k ( x ⃗ ; μ ⃗ k , Σ k ) p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k) p k ( x ; μ k , Σ k ) x ⃗ \mathbf{\vec x} x k k k μ ⃗ k , Σ k \vec \mu_k,\Sigma_k μ k , Σ k 混合系数 α k ≥ 0 , ∑ k = 1 K α k = 1 \alpha_k \ge 0, \sum_{k=1}^{K}\alpha_k=1 α k ≥ 0 , ∑ k = 1 K α k = 1 令 f ( x ⃗ ) ∈ Y f(\mathbf{\vec x})\in \mathcal Y f ( x ) ∈ Y f f f x ⃗ \mathbf{\vec x} x Θ ∈ { 1 , 2 , ⋯ , K } \Theta \in \{1,2,\cdots,K\} Θ ∈ { 1 , 2 , ⋯ , K } x ⃗ \mathbf{\vec x} x
根据最大化后验概率,有:
f ( x ⃗ ) = arg max j ∈ Y p ( y = j ∣ x ⃗ ) f(\mathbf{\vec x})=\arg\max_{j\in \mathcal Y}p(y=j\mid \mathbf{\vec x}) f ( x ) = arg j ∈ Y max p ( y = j ∣ x )
考虑到 p ( y = j ∣ x ⃗ ) = ∑ k = 1 K p ( y = j , Θ = k ∣ x ⃗ ) p(y=j\mid \mathbf{\vec x})=\sum_{k=1}^{K}p(y=j,\Theta=k\mid \mathbf{\vec x}) p ( y = j ∣ x ) = ∑ k = 1 K p ( y = j , Θ = k ∣ x )
f ( x ⃗ ) = arg max j ∈ Y ∑ k = 1 K p ( y = j , Θ = k ∣ x ⃗ ) f(\mathbf{\vec x})=\arg\max_{j\in \mathcal Y}\sum_{k=1}^{K}p(y=j,\Theta=k\mid \mathbf{\vec x}) f ( x ) = arg j ∈ Y max k = 1 ∑ K p ( y = j , Θ = k ∣ x )
由于 p ( y = j , Θ = k ∣ x ⃗ ) = p ( y = j ∣ Θ = k , x ⃗ ) ⋅ p ( Θ = k ∣ x ⃗ ) p(y=j,\Theta=k\mid \mathbf{\vec x})=p(y=j\mid \Theta=k,\mathbf{\vec x})\cdot p(\Theta=k\mid \mathbf{\vec x}) p ( y = j , Θ = k ∣ x ) = p ( y = j ∣ Θ = k , x ) ⋅ p ( Θ = k ∣ x )
f ( x ⃗ ) = arg max j ∈ Y ∑ k = 1 K p ( y = j ∣ Θ = k , x ⃗ ) ⋅ p ( Θ = k ∣ x ⃗ ) f(\mathbf{\vec x})=\arg\max_{j\in \mathcal Y}\sum_{k=1}^{K}p(y=j\mid \Theta=k,\mathbf{\vec x})\cdot p(\Theta=k\mid \mathbf{\vec x}) f ( x ) = arg j ∈ Y max k = 1 ∑ K p ( y = j ∣ Θ = k , x ) ⋅ p ( Θ = k ∣ x )
p ( Θ = k ∣ x ⃗ ) p(\Theta=k\mid \mathbf{\vec x}) p ( Θ = k ∣ x ) x ⃗ \mathbf{\vec x} x k k k
p ( Θ = k ∣ x ⃗ ) = α k p k ( x ⃗ ; μ ⃗ k , Σ k ) ∑ k = 1 K α k p k ( x ⃗ ; μ ⃗ k , Σ k ) p(\Theta=k\mid \mathbf{\vec x})=\frac{\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k)}{\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k)} p ( Θ = k ∣ x ) = ∑ k = 1 K α k p k ( x ; μ k , Σ k ) α k p k ( x ; μ k , Σ k )
p ( y = j ∣ Θ = k , x ⃗ ) p(y=j\mid \Theta=k,\mathbf{\vec x}) p ( y = j ∣ Θ = k , x ) x ⃗ \mathbf{\vec x} x k k k j j j
在 f ( x ⃗ ) = arg max j ∈ Y ∑ k = 1 K p ( y = j ∣ Θ = k , x ⃗ ) ⋅ p ( Θ = k ∣ x ⃗ ) f(\mathbf{\vec x})=\arg\max_{j\in \mathcal Y}\sum_{k=1}^{K}p(y=j\mid \Theta=k,\mathbf{\vec x})\cdot p(\Theta=k\mid \mathbf{\vec x}) f ( x ) = arg max j ∈ Y ∑ k = 1 K p ( y = j ∣ Θ = k , x ) ⋅ p ( Θ = k ∣ x ) p ( y = j ∣ Θ = k , x ⃗ ) p(y=j\mid \Theta=k,\mathbf{\vec x}) p ( y = j ∣ Θ = k , x ) y y y p ( Θ = k ∣ x ⃗ ) p(\Theta=k\mid \mathbf{\vec x}) p ( Θ = k ∣ x )
因此通过引入大量的未标记数据,对 p ( y = j , Θ = k ∣ x ⃗ ) p(y=j,\Theta=k\mid \mathbf{\vec x}) p ( y = j , Θ = k ∣ x )
给定标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \} D u = { x l + 1 , x l + 2 , ⋯ , x l + u } l ≪ u , l + u = N l \ll u,\quad l+u=N l ≪ u , l + u = N
假设所有样本独立同分布,且都是由同一个高斯混合模型 p ( x ⃗ ) = ∑ k = 1 K α k p k ( x ⃗ ; μ ⃗ k , Σ k ) p(\mathbf{\vec x})=\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k) p ( x ) = ∑ k = 1 K α k p k ( x ; μ k , Σ k )
高斯混合模型的参数 { ( α k , μ ⃗ k , Σ k ) , k = 1 , 2 , ⋯ , K } \{(\alpha_k,\vec \mu_k,\Sigma_k), k=1,2,\cdots,K\} {( α k , μ k , Σ k ) , k = 1 , 2 , ⋯ , K }
D l ⋃ D u \mathbb D_l \bigcup\mathbb D_u D l ⋃ D u
L = ∑ ( x ⃗ i , y i ) ∈ D l log ( ∑ k = 1 K α k p k ( x ⃗ i ; μ ⃗ k , Σ k ) ⋅ p ( y i ∣ Θ = k , x ⃗ i ) ) + ∑ x ⃗ i ∈ D u log ( ∑ k = 1 K α k p k ( x ⃗ i ; μ ⃗ k , Σ k ) ) \mathcal L=\sum_{(\mathbf{\vec x}_i,y_i)\in \mathbb D_l}\log\left(\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x}_i;\vec \mu_k,\Sigma_k)\cdot p(y_i\mid\Theta=k,\mathbf{\vec x}_i)\right) \\ +\sum_{\mathbf{\vec x}_i \in \mathbb D_u}\log\left(\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x}_i;\vec \mu_k,\Sigma_k)\right) L = ( x i , y i ) ∈ D l ∑ log ( k = 1 ∑ K α k p k ( x i ; μ k , Σ k ) ⋅ p ( y i ∣ Θ = k , x i ) ) + x i ∈ D u ∑ log ( k = 1 ∑ K α k p k ( x i ; μ k , Σ k ) )
第一项对数项中,为联合概率 p ( x ⃗ i , y i ) p(\mathbf{\vec x}_i,y_i) p ( x i , y i )
p ( x ⃗ i , y i ) = p ( y i ∣ x ⃗ i ) p ( x ⃗ i ) = ∑ k = 1 K α k p k ( x ⃗ i ; μ ⃗ k , Σ k ) ⋅ p ( y i ∣ Θ = k , x ⃗ i ) p(\mathbf{\vec x}_i,y_i)=p(y_i\mid \mathbf{\vec x}_i)p(\mathbf{\vec x}_i)=\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x}_i;\vec \mu_k,\Sigma_k)\cdot p(y_i\mid \Theta=k,\mathbf{\vec x}_i) p ( x i , y i ) = p ( y i ∣ x i ) p ( x i ) = k = 1 ∑ K α k p k ( x i ; μ k , Σ k ) ⋅ p ( y i ∣ Θ = k , x i )
第二项对数项中,为概率 p ( x ⃗ i ) p(\mathbf{\vec x}_i) p ( x i )
p ( x ⃗ i ) = ∑ k = 1 K α k p k ( x ⃗ i ; μ ⃗ k , Σ k ) p(\mathbf{\vec x}_i)=\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x}_i;\vec \mu_k,\Sigma_k) p ( x i ) = k = 1 ∑ K α k p k ( x i ; μ k , Σ k )
高斯混合模型参数估计可以用EM算法求解。迭代更新步骤为:
E步:根据当前模型参数 { ( α ^ k , μ ⃗ k ^ , Σ ^ k ) , k = 1 , 2 , ⋯ , K } \{(\hat \alpha_k,\hat{\vec \mu_k},\hat \Sigma_k), k=1,2,\cdots,K\} {( α ^ k , μ k ^ , Σ ^ k ) , k = 1 , 2 , ⋯ , K } x ⃗ i \mathbf{\vec x}_i x i γ i , k = α ^ k p k ( x ⃗ i ; μ ⃗ k ^ , Σ ^ k ) ∑ k = 1 K α ^ k p k ( x ⃗ i ; μ ⃗ k ^ , Σ ^ k ) \gamma_{i,k}=\frac{\hat \alpha_k p_k(\mathbf{\vec x}_i;\hat {\vec \mu_k},\hat \Sigma_k)}{\sum_{k=1}^{K}\hat \alpha_k p_k(\mathbf{\vec x}_i;\hat {\vec \mu_k},\hat\Sigma_k)} γ i , k = ∑ k = 1 K α ^ k p k ( x i ; μ k ^ , Σ ^ k ) α ^ k p k ( x i ; μ k ^ , Σ ^ k )
M步:基于 γ i , k \gamma_{i,k} γ i , k
令 l k l_k l k k k k
μ ⃗ k ^ = 1 ∑ x ⃗ i ∈ D u γ i , k + l k ( ∑ x ⃗ i ∈ D u γ i , k x ⃗ i + ∑ ( x ⃗ i , y i ) ∈ D l a n d y i = k γ i , k x ⃗ i ) Σ ^ k = 1 ∑ x ⃗ i ∈ D u γ i , k + l k ( ∑ x ⃗ i ∈ D u γ i , k ( x ⃗ i − μ ⃗ k ^ ) ( x ⃗ i − μ ⃗ k ^ ) T + ∑ ( x ⃗ i , y i ) ∈ D l a n d y i = k γ i , k ( x ⃗ i − μ ⃗ k ^ ) ( x ⃗ i − μ ⃗ k ^ ) T ) α ^ k = 1 N ( ∑ x ⃗ i ∈ D u γ i , k + l k ) \hat{\vec \mu_k}=\frac{1}{\sum_{\mathbf{\vec x}_i\in \mathbb D_u}\gamma_{i,k}+l_k}\left(\sum_{\mathbf{\vec x}_i\in \mathbb D_u} \gamma_{i,k}\mathbf{\vec x}_i+\sum_{(\mathbf{\vec x}_i,y_i)\in \mathbb D_l \;and\; y_i=k} \gamma_{i,k}\mathbf{\vec x}_i\right)\\ \hat \Sigma_k=\frac{1}{\sum_{\mathbf{\vec x}_i\in \mathbb D_u}\gamma_{i,k}+l_k}\left(\sum_{\mathbf{\vec x}_i\in \mathbb D_u} \gamma_{i,k}(\mathbf{\vec x}_i-\hat{\vec \mu_k})(\mathbf{\vec x}_i-\hat{\vec \mu_k})^{T}+\\ \sum_{(\mathbf{\vec x}_i,y_i)\in \mathbb D_l \;and\; y_i=k} \gamma_{i,k}(\mathbf{\vec x}_i-\hat{\vec \mu_k})(\mathbf{\vec x}_i-\hat{\vec \mu_k})^{T}\right)\\ \hat \alpha_k=\frac 1N\left(\sum_{\mathbf{\vec x}_i\in \mathbb D_u}\gamma_{i,k}+l_k\right) μ k ^ = ∑ x i ∈ D u γ i , k + l k 1 ⎝ ⎛ x i ∈ D u ∑ γ i , k x i + ( x i , y i ) ∈ D l an d y i = k ∑ γ i , k x i ⎠ ⎞ Σ ^ k = ∑ x i ∈ D u γ i , k + l k 1 ⎝ ⎛ x i ∈ D u ∑ γ i , k ( x i − μ k ^ ) ( x i − μ k ^ ) T + ( x i , y i ) ∈ D l an d y i = k ∑ γ i , k ( x i − μ k ^ ) ( x i − μ k ^ ) T ⎠ ⎞ α ^ k = N 1 ⎝ ⎛ x i ∈ D u ∑ γ i , k + l k ⎠ ⎞
以上过程不断迭代直至收敛,即可获得模型参数。
预测过程:根据式子:
f ( x ⃗ ) = arg max j ∈ Y ∑ k = 1 K p ( y = j ∣ Θ = k , x ⃗ ) ⋅ p ( Θ = k ∣ x ⃗ ) p ( Θ = k ∣ x ⃗ ) = α k p k ( x ⃗ ; μ ⃗ k , Σ k ) ∑ k = 1 K α k p k ( x ⃗ ; μ ⃗ k , Σ k ) f(\mathbf{\vec x})=\arg\max_{j\in \mathcal Y}\sum_{k=1}^{K}p(y=j\mid \Theta=k,\mathbf{\vec x})\cdot p(\Theta=k\mid \mathbf{\vec x})\\ p(\Theta=k\mid \mathbf{\vec x})=\frac{\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k)}{\sum_{k=1}^{K}\alpha_k p_k(\mathbf{\vec x};\vec \mu_k,\Sigma_k)} f ( x ) = arg j ∈ Y max k = 1 ∑ K p ( y = j ∣ Θ = k , x ) ⋅ p ( Θ = k ∣ x ) p ( Θ = k ∣ x ) = ∑ k = 1 K α k p k ( x ; μ k , Σ k ) α k p k ( x ; μ k , Σ k )
来对样本 x ⃗ \mathbf{\vec x} x
特点 优点:方法简单,易于实现。在有标记数据极少的情况下,往往比其他方法性能更好。
缺点:模型假设必须准确,即假设的生成式模型必须与真实数据分布吻合,否则利用未标记数据反倒会降低泛化性能。
在现实任务中往往很难事先做出准确的模型假设,除非拥有充分可靠的领域知识。
基于分歧的方法 基于分歧的方法disagreement-based methods使用多个学习器,学习器之间的分歧disagreement对未标记数据的利用至关重要。
协同训练co-traning是此类方法的重要代表。它最初是针对多视图multi-view数据设计的,因此也被视作多视图学习multi-view learning的代表。
数据视图 在不少现实应用中,一个数据对象往往同时拥有多个属性集attribute-set。每个属性集就构成了一个视图。
假设数据集为 D = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ N , y N ) } \mathbb D=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_N,y_N)\} D = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N )} x ⃗ i = ( x i , 1 , x i , 2 , ⋯ , x i , d ) T \mathbf{\vec x}_i=(x_{i,1},x_{i,2},\cdots,x_{i,d})^{T} x i = ( x i , 1 , x i , 2 , ⋯ , x i , d ) T x = { x 1 , x 2 , ⋯ , x d } \mathbf x=\{x_1, x_2,\cdots, x_d\} x = { x 1 , x 2 , ⋯ , x d } x = x ( 1 ) ⋃ x ( 2 ) \mathbf x= \mathbf x^{(1)}\bigcup \mathbf x^{(2)} x = x ( 1 ) ⋃ x ( 2 )
x ( 1 ) = { x 1 , x 2 , ⋯ , x d 1 } , x ( 2 ) = { x d 1 + 1 , x d 1 + 2 , ⋯ , x d } \mathbf x^{(1)}=\{x_1, x_2,\cdots, x_{d_1}\},\quad \mathbf x^{(2)}=\{x_{d_1+1}, x_{d_1+2},\cdots, x_{d}\} x ( 1 ) = { x 1 , x 2 , ⋯ , x d 1 } , x ( 2 ) = { x d 1 + 1 , x d 1 + 2 , ⋯ , x d }
即将属性划分为两个属性集,前 d 1 d_1 d 1 d − d 1 d-d_1 d − d 1
原始样本 x ⃗ i \mathbf{\vec x}_i x i < x ⃗ i ( 1 ) , x ⃗ i ( 2 ) > <\mathbf{\vec x}_i^{(1)},\mathbf{\vec x}_i^{(2)}> < x i ( 1 ) , x i ( 2 ) > ( < x ⃗ i ( 1 ) , x ⃗ i ( 2 ) > , y i ) (<\mathbf{\vec x}_i^{(1)},\mathbf{\vec x}_i^{(2)}>,y_i) ( < x i ( 1 ) , x i ( 2 ) > , y i ) 如: <身高、体重、年龄、学历、爱好、工作> 可以划分为两个属性集: <身高、体重、年龄>以及<学历、爱好、工作> 。
假设不同视图具有相容性compatibility:即其所包含的关于输出空间 Y \mathcal Y Y
令 Y 1 \mathcal Y^{1} Y 1 Y 2 \mathcal Y^{2} Y 2 Y = Y 1 = Y 2 \mathcal Y=\mathcal Y^{1}=\mathcal Y^{2} Y = Y 1 = Y 2
注意:这里仅要求标记空间相同,并没有要求每个标记相同。
自学习self-training Self-training 是最简单的半监督方法之一,其主要思想是找到一种方法,用未标记的数据集来扩充已标记的数据集。算法流程如下:
首先,利用已标记的数据来训练一个好的模型,然后使用这个模型对未标记的数据进行标记。 然后,进行伪标签的生成,因为已训练好的模型对未标记数据的所有预测都不可能都是完全正确的,因此对于经典的 Self-training,通常是使用分数阈值(confidence score)过滤部分预测,以选择出未标记数据的预测标签的一个子集。 其次,将生成的伪标签与原始的标记数据相结合,并在合并后数据上进行联合训练。 整个过程可以重复 n 次,直到达到收敛。 Self-training 最大的问题在就在于伪标签非常的 noisy,会使得模型朝着错误的方向发展。此后文章大多数都是为了解决这个问题。
简单解释一下:
将初始的有标签数据集作为初始的训练集 ( X t r a i n , y t r a i n ) = ( X l , y l ) (X_{train},y_{train})=(X_{l},y_{l}) ( X t r ain , y t r ain ) = ( X l , y l ) C i n t C_{int} C in t
利用 C i n t C_{int} C in t X u X_u X u ( X c o n f , y c o n f ) (X_{conf},y_{conf}) ( X co n f , y co n f )
从 X u X_u X u ( X c o n f , y c o n f ) (X_{conf},y_{conf}) ( X co n f , y co n f )
将 ( X c o n f , y c o n f ) (X_{conf},y_{conf}) ( X co n f , y co n f ) ( X t r a i n , y t r a i n ) ← ( X l , y l ) ∪ ( X c o n f , y c o n f ) (X_{train},y_{train})\leftarrow(X_{l},y_{l})\cup(X_{conf},y_{conf}) ( X t r ain , y t r ain ) ← ( X l , y l ) ∪ ( X co n f , y co n f )
根据新的训练集训练新的分类器,重复步骤 2 到 5 直到满足停止条件(例如所有无标签样本都被标记完了) 最后得到的分类器就是最终的分类器。
Self-training 的主要缺点是模型无法纠正自己的错误。如果模型对自己的分类结果很有 “自信”,但这是盲目自信,分类结果是错的,那它就会在训练中放大误差。此外,如果数据集 U U U L L L C C C U U U
协同训练算法 协同训练正是很好地利用了多视图数据的 “相容互补性 ”,其基本的思想是:首先在每个视图上基于有标记样本分别训练一个初始分类器,然后让每个分类器去挑选分类置信度最高的未标记样本并赋予标记,并将带有伪标记的样本数据传给另一个分类器作为新增的有标记样本用于训练更新,这个 “互相学习、共同进步” 的过程不断迭代进行,直到两个分类器都不再发生变化,或达到预先设定的轮数为止。
协同训练充分利用了多视图的相容互补性。
假设数据拥有两个充分且条件独立视图。
充分:指每个视图都包含足以产生最优学习器的信息。 条件独立:指在给定类别标记条件下,两个视图独立。 此时,可以用一个简单的办法来利用未标记数据:
首先在每个视图上,基于有标记样本,分别训练出一个分类器。 然后让每个分类器分别去挑选自己最有把握的未标记样本赋予伪标记,并将伪标记样本提供给另一个分类器作为新增的有标记样本用于训练更新。 该 “互相学习、共同进步” 的过程不断迭代进行,直到两个分类器都不再发生变化,或者到达指定的迭代轮数为止。 注意:
如果在每轮学习中都考察分类器在所有未标记样本上的分类置信度,则会有很大的计算开销。因此在算法中使用了未标记样本缓冲池。 分类置信度的估计因基学习算法而异。 协同训练算法:
输入:
有标记样本集 D l = { ( < x ⃗ 1 ( 1 ) , x ⃗ 1 ( 2 ) > , y 1 ) , ( < x ⃗ 2 ( 1 ) , x ⃗ 2 ( 2 ) > , y 2 ) , ⋯ , ( < x ⃗ l ( 1 ) , x ⃗ l ( 2 ) > , y l ) } \mathbb D_l=\{(<\mathbf{\vec x}_1^{(1)},\mathbf{\vec x}_1^{(2)}>,y_1),(<\mathbf{\vec x}_2^{(1)},\mathbf{\vec x}_2^{(2)}>,y_2),\cdots,(<\mathbf{\vec x}_l^{(1)},\mathbf{\vec x}_l^{(2)}>,y_l)\} D l = {( < x 1 ( 1 ) , x 1 ( 2 ) > , y 1 ) , ( < x 2 ( 1 ) , x 2 ( 2 ) > , y 2 ) , ⋯ , ( < x l ( 1 ) , x l ( 2 ) > , y l )} 未标记样本集 D u = { < x ⃗ l + 1 ( 1 ) , x ⃗ l + 1 ( 2 ) > , < x ⃗ l + 2 ( 1 ) , x ⃗ l + 2 ( 2 ) > , ⋯ , < x ⃗ l + u ( 1 ) , x ⃗ l + u ( 2 ) > } , l + u = N \mathbb D_u=\{<\mathbf{\vec x}_{l+1}^{(1)},\mathbf{\vec x}_{l+1}^{(2)}>, <\mathbf{\vec x}_{l+2}^{(1)},\mathbf{\vec x}_{l+2}^{(2)}>,\cdots, <\mathbf{\vec x}_{l+u}^{(1)},\mathbf{\vec x}_{l+u}^{(2)}> \},l+u=N D u = { < x l + 1 ( 1 ) , x l + 1 ( 2 ) > , < x l + 2 ( 1 ) , x l + 2 ( 2 ) > , ⋯ , < x l + u ( 1 ) , x l + u ( 2 ) > } , l + u = N 缓冲池大小 s s s 每轮挑选的正例数量 p p p 每轮挑选的反例数量 n n n 基学习算法 f f f 学习轮数 T T T 输出:未标记样本的预测结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T},\hat y_i \in \{1,2,\cdots,K\},i=l+1,l+2,\cdots,l+u y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u
步骤:
从 D u \mathbb D_u D u s s s D s \mathbb D_s D s
D u = D u − D s \mathbb D_u=\mathbb D_u-\mathbb D_s D u = D u − D s
从 D l \mathbb D_l D l D ( 1 ) , D ( 2 ) \mathbb D^{(1)},\mathbb D^{(2)} D ( 1 ) , D ( 2 )
D l ( 1 ) = { ( x ⃗ 1 ( 1 ) , y 1 ) , ( x ⃗ 2 ( 1 ) , y 2 ) , ⋯ , ( x ⃗ l ( 1 ) , y l ) } D l ( 2 ) = { ( x ⃗ 1 ( 2 ) , y 1 ) , ( x ⃗ 2 ( 2 ) , y 2 ) , ⋯ , ( x ⃗ l ( 2 ) , y l ) } \mathbb D_l^{(1)}=\{( \mathbf{\vec x}_1^{(1)} ,y_1),( \mathbf{\vec x}_2^{(1)}, y_2),\cdots,( \mathbf{\vec x}_l^{(1)} ,y_l)\}\\ \mathbb D_l^{(2)}=\{( \mathbf{\vec x}_1^{(2)} ,y_1),( \mathbf{\vec x}_2^{(2)}, y_2),\cdots,( \mathbf{\vec x}_l^{(2)} ,y_l)\} D l ( 1 ) = {( x 1 ( 1 ) , y 1 ) , ( x 2 ( 1 ) , y 2 ) , ⋯ , ( x l ( 1 ) , y l )} D l ( 2 ) = {( x 1 ( 2 ) , y 1 ) , ( x 2 ( 2 ) , y 2 ) , ⋯ , ( x l ( 2 ) , y l )}
开始迭代,迭代终止条件是:迭代收敛或者迭代次数达到 T T T
从 D s \mathbb D_s D s m m m D s ( 1 ) , D s ( 2 ) \mathbb D_s^{(1)},\mathbb D_s^{(2)} D s ( 1 ) , D s ( 2 )
D s ( 1 ) = { x ⃗ s 1 ( 1 ) , x ⃗ s 2 ( 1 ) , ⋯ , x ⃗ s m ( 1 ) } D s ( 2 ) = { x ⃗ s 1 ( 2 ) , x ⃗ s 2 ( 2 ) , ⋯ , x ⃗ s m ( 2 ) } \mathbb D_s^{(1)}=\{\mathbf{\vec x}_{s1}^{(1)} , \mathbf{\vec x}_{s2}^{(1)},\cdots,\mathbf{\vec x}_{sm}^{(1)} \}\\ \mathbb D_s^{(2)}=\{\mathbf{\vec x}_{s1}^{(2)} , \mathbf{\vec x}_{s2}^{(2)},\cdots, \mathbf{\vec x}_{sm}^{(2)} \} D s ( 1 ) = { x s 1 ( 1 ) , x s 2 ( 1 ) , ⋯ , x s m ( 1 ) } D s ( 2 ) = { x s 1 ( 2 ) , x s 2 ( 2 ) , ⋯ , x s m ( 2 ) }
考察视图一:
利用 D l ( 1 ) \mathbb D_l^{(1)} D l ( 1 ) f f f f 1 f_1 f 1 然后考察 f 1 f_1 f 1 D s ( 1 ) \mathbb D_s^{(1)} D s ( 1 ) p p p D p ( 1 ) ⊂ D s \mathbb D_p^{(1)} \subset \mathbb D_s D p ( 1 ) ⊂ D s n n n D n ( 1 ) ⊂ D s \mathbb D_n^{(1)} \subset \mathbb D_s D n ( 1 ) ⊂ D s 然后将 D p ( 1 ) \mathbb D_p^{(1)} D p ( 1 ) D n ( 1 ) \mathbb D_n^{(1)} D n ( 1 ) D ~ p ( 2 ) = { ( x ⃗ i ( 2 ) , 1 ) ∣ x ⃗ i ( 1 ) ∈ D p ( 1 ) } D ~ n ( 2 ) = { ( x ⃗ i ( 2 ) , − 1 ) ∣ x ⃗ i ( 1 ) ∈ D n ( 1 ) } \tilde {\mathbb D}_p^{(2)}=\{(\mathbf{\vec x}_i^{(2)},1)\mid \mathbf{\vec x}_i^{(1)} \in \mathbb D_p^{(1)} \}\\ \tilde {\mathbb D}_n^{(2)}=\{(\mathbf{\vec x}_i^{(2)},-1)\mid \mathbf{\vec x}_i^{(1)} \in \mathbb D_n^{(1)} \} D ~ p ( 2 ) = {( x i ( 2 ) , 1 ) ∣ x i ( 1 ) ∈ D p ( 1 ) } D ~ n ( 2 ) = {( x i ( 2 ) , − 1 ) ∣ x i ( 1 ) ∈ D n ( 1 ) }
这里并没有简单的将 D p ( 1 ) \mathbb D_p^{(1)} D p ( 1 ) D n ( 1 ) \mathbb D_n^{(1)} D n ( 1 )
D s = D s − ( D p ( 1 ) ⋃ D n ( 1 ) ) \mathbb D_s=\mathbb D_s-(\mathbb D_p^{(1)}\bigcup \mathbb D_n^{(1)}) D s = D s − ( D p ( 1 ) ⋃ D n ( 1 ) ) D s ( 2 ) \mathbb D_s^{(2)} D s ( 2 ) D s ( 2 ) \mathbb D_s^{(2)} D s ( 2 )
考察视图二:
利用 D l ( 2 ) \mathbb D_l^{(2)} D l ( 2 ) f f f f 2 f_2 f 2 然后考察 f 2 f_2 f 2 D s ( 2 ) \mathbb D_s^{(2)} D s ( 2 ) p p p D p ( 2 ) ⊂ D s \mathbb D_p^{(2)}\subset \mathbb D_s D p ( 2 ) ⊂ D s n n n D n ( 2 ) ⊂ D s \mathbb D_n^{(2)} \subset \mathbb D_s D n ( 2 ) ⊂ D s 然后将 D p ( 2 ) \mathbb D_p^{(2)} D p ( 2 ) D n 2 D_n^{2} D n 2 D ~ p ( 1 ) = { ( x ⃗ i ( 1 ) , 1 ) ∣ x ⃗ i ( 2 ) ∈ D p ( 2 ) } D ~ n ( 1 ) = { ( x ⃗ i ( 1 ) , − 1 ) ∣ x ⃗ i ( 2 ) ∈ D n ( 2 ) } \tilde {\mathbb D}_p^{(1)}=\{(\mathbf{\vec x}_i^{(1)},1)\mid \mathbf{\vec x}_i^{(2)} \in \mathbb D_p^{(2)} \}\\ \tilde {\mathbb D}_n^{(1)}=\{(\mathbf{\vec x}_i^{(1)},-1)\mid \mathbf{\vec x}_i^{(2)} \in \mathbb D_n^{(2)} \} D ~ p ( 1 ) = {( x i ( 1 ) , 1 ) ∣ x i ( 2 ) ∈ D p ( 2 ) } D ~ n ( 1 ) = {( x i ( 1 ) , − 1 ) ∣ x i ( 2 ) ∈ D n ( 2 ) }
D s = D s − ( D p ( 2 ) ⋃ D n ( 2 ) ) \mathbb D_s=\mathbb D_s-(\mathbb D_p^{(2)}\bigcup \mathbb D_n^{(2)}) D s = D s − ( D p ( 2 ) ⋃ D n ( 2 ) ) 如果 f 1 , f 2 f_1,f_2 f 1 , f 2 如何判断是否发生改变?通常可以考察它们的预测结果是否一致
更新 D l ( 1 ) , D l ( 2 ) \mathbb D_l^{(1)},\mathbb D_l^{(2)} D l ( 1 ) , D l ( 2 ) D l ( 1 ) = D l ( 1 ) ⋃ ( D ~ p ( 1 ) ⋃ D ~ n ( 1 ) ) D l ( 2 ) = D l ( 2 ) ⋃ ( D ~ p ( 2 ) ⋃ D ~ n ( 2 ) ) \mathbb D_l^{(1)}=\mathbb D_l^{(1)}\bigcup(\tilde {\mathbb D}_p^{(1)}\bigcup \tilde {\mathbb D}_n^{(1)})\\ \mathbb D_l^{(2)}=\mathbb D_l^{(2)}\bigcup(\tilde {\mathbb D}_p^{(2)}\bigcup \tilde {\mathbb D}_n^{(2)}) D l ( 1 ) = D l ( 1 ) ⋃ ( D ~ p ( 1 ) ⋃ D ~ n ( 1 ) ) D l ( 2 ) = D l ( 2 ) ⋃ ( D ~ p ( 2 ) ⋃ D ~ n ( 2 ) )
最终得到分类器 f 1 , f 2 f_1,f_2 f 1 , f 2 D u \mathbb D_u D u y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T} y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T
性质 协同训练过程虽然简单,但是理论证明:若两个视图充分且条件独立,则可利用未标记样本通过协同训练将弱分类器的泛化性能提升到任意高。
不过视图的条件独立性在现实任务中通常很难满足,因此性能提升幅度没有那么大。 但研究表明,即便在更弱的条件下,协同训练仍可以有效提升弱分类器的性能。 协同训练算法本身是为多试图数据而设计的,但此后出现了一些能在单视图数据上使用的变体算法。
它们或是使用不同的学习算法,或是使用不同的数据采样,甚至使用不同的参数设置来产生不同的学习器,也能有效利用未标记数据来提升性能。
后续理论研究表明,此类算法事实上无需数据拥有多试图,仅需弱学习器之间具有显著的分歧(或者差异),即可通过相互提供伪标记样本的方式来提升泛化性能。
而不同视图、不同算法、不同数据采样、不同参数设置等,都是产生差异的渠道,而不是必备条件。
基于分歧的方法只需要采用合适的基学习器,就能较少受到模型假设、损失函数非凸性和数据规模问题的影响,学习方法简单有效、理论基础相对坚实、使用范围较为广泛。
为了使用此类方法,需要能生成具有显著分歧、性能尚可的多个学习器。 但当有标记样本较少,尤其是数据不具有多试图时,要做到这一点并不容易,需要巧妙的设计。 Tri-training(三体训练法) 这是周志华等人于 2005 提出的一种算法,也是迄今为止所有多视图训练算法中知名度最高的一种,它会训练三个独立模型,然后用三者的一致性减少对不含标签数据的预测偏差。
Tri-training 的一个主要前提是初始模型必须是多样的,这和 Democratic Co-learning 一样,但后者实现的方法是使用不同的的架构,而前者则是从原始训练数据 L 中用 Bootstrap 采样机制获得不同变体 S i S_i S i m 1 m_1 m 1 m 2 m_2 m 2 m 3 m_3 m 3 m j m_j m j m k m_k m k m i m_i m i m i m_i m i
其他阅读推荐:一文概览能生成代理标签的半监督学习算法
其中介绍了
Self-training Multi-view training Self-ensembling 相关工具和领域
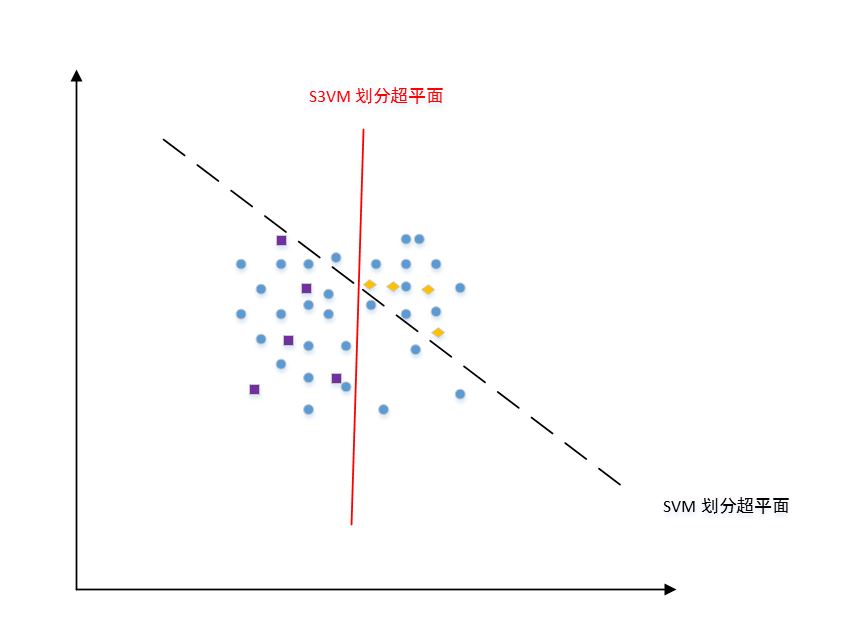
半监督 SVM 半监督支持向量机Semi-Supervised Support Vector Machine:S3VM 是支持向量机在半监督学习上的推广。
在不考虑未标记样本时,支持向量机试图找到最大间隔划分超平面;在考虑未标记样本之后,S3VM试图找到能将两类有标记样本分开,且穿过数据低密度区域的划分超平面。
如下图中,蓝色点为未标记样本,紫色点为正类样本,黄色点为负类样本。
半监督 SVM 的基本假设是:低密度分隔low-density separation。这是聚类假设在考虑了线性超平面划分后的推广。
TVSM 半监督支持向量机中最著名的是 TSVM:Transductive Support Vector Machine。与标准SVM一样,TSVM也是针对二分类问题的学习方法。
TSVM试图考虑对未标记样本进行各种可能的标记指派label assignment:
尝试将每个未标记样本分别作为正例或者反例。 然后在所有这些结果中,寻求一个在所有样本(包括有标记样本和进行了标记指派的未标记样本)上间隔最大化的划分超平面。 一旦划分超平面得以确定,未标记样本的最终标记指派就是其预测结果。 给定标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \} D u = { x l + 1 , x l + 2 , ⋯ , x l + u } l ≪ u , l + u = N , y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋯ , l l \ll u,\; l+u=N,\;y_i \in \{-1,+1\},i=1,2,\cdots,l l ≪ u , l + u = N , y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋯ , l
TSVM学习的目标是:为 D u \mathbb D_u D u y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { − 1 , + 1 } , i = l + 1 , l + 2 , ⋯ , N \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T},\hat y_i \in \{-1,+1\},i=l+1,l+2,\cdots,N y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { − 1 , + 1 } , i = l + 1 , l + 2 , ⋯ , N
min w ⃗ , b , y ⃗ ^ , ξ ⃗ 1 2 ∣ ∣ w ⃗ ∣ ∣ 2 2 + C l ∑ i = 1 l ξ i + C u ∑ i = l + 1 N ξ i s . t . y i ( w ⃗ T x ⃗ i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , l y ^ i ( w ⃗ T x ⃗ i + b ) ≥ 1 − ξ i , i = l + 1 , l + 2 , ⋯ , N ξ i ≥ 0 , i = 1 , 2 , ⋯ , N \min_{\mathbf{\vec w},b,\hat{\mathbf{\vec y}},\vec\xi} \frac 12 ||\mathbf{\vec w}||_2^{2}+C_l\sum_{i=1}^{l}\xi_i+C_u\sum_{i=l+1}^{N}\xi_i\\ s.t.\; y_i(\mathbf{\vec w}^{T}\mathbf{\vec x}_i+b) \ge 1-\xi_i,\quad i=1,2,\cdots,l\\ \hat y_i(\mathbf{\vec w}^{T}\mathbf{\vec x}_i+b) \ge 1-\xi_i,\quad i=l+1,l+2,\cdots,N\\ \xi_i \ge 0,\quad i=1,2,\cdots,N w , b , y ^ , ξ min 2 1 ∣∣ w ∣ ∣ 2 2 + C l i = 1 ∑ l ξ i + C u i = l + 1 ∑ N ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , l y ^ i ( w T x i + b ) ≥ 1 − ξ i , i = l + 1 , l + 2 , ⋯ , N ξ i ≥ 0 , i = 1 , 2 , ⋯ , N
其中:
( w ⃗ , b ) (\mathbf{\vec w},b) ( w , b )
ξ ⃗ \vec \xi ξ
ξ i , i = 1 , 2 , ⋯ , l \xi_i ,i=1,2,\cdots,l ξ i , i = 1 , 2 , ⋯ , l ξ i , i = l + 1 , l + 2 , ⋯ , N \xi_i ,i=l+1,l+2,\cdots,N ξ i , i = l + 1 , l + 2 , ⋯ , N C l , C u C_l,C_u C l , C u
TSVM尝试未标记样本的各种标记指派是一个穷举过程,仅当未标记样本很少时才有可能直接求解。因此通常情况下,必须考虑更高效的优化策略。
TSVM 采用局部搜索来迭代地寻求上式的近似解。具体来说:
首先利用有标记样本学得一个SVM:即忽略上式中关于 D u \mathbb D_u D u y ⃗ ^ \hat{\mathbf{\vec y}} y ^
然后利用这个SVM 对未标记数据进行标记指派:即将SVM预测的结果作为伪标记pseudo-label赋予未标记样本。
此时 y ⃗ ^ \hat{\mathbf{\vec y}} y ^ SVM问题。于是求解可以解出新的划分超平面和松弛向量。 注意到此时的未标记样本的伪标记很可能不准确,因此 C u C_u C u C l C_l C l 接下来, TSVM 找出两个标记指派为异类且很可能发生错误的未标记样本,交换它们的标记,再重新基于上式求解出更新后的划分超平面和松弛向量。
再接下来,TSVM 再找出两个标记指派为异类且很可能发生错误的未标记样本,交换它们的标记,再重新基于上式求解出更新后的划分超平面和松弛向量。
…
标记指派调整完成后,逐渐增大 C u C_u C u C u C_u C u
TSVM算法算法输入:
有标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋯ , l y_i \in \{-1,+1\},i=1,2,\cdots,l y i ∈ { − 1 , + 1 } , i = 1 , 2 , ⋯ , l 未标记样本集 D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \} D u = { x l + 1 , x l + 2 , ⋯ , x l + u } l ≪ u , l + u = N l \ll u,\quad l+u=N l ≪ u , l + u = N 折中参数 C l , C u C_l,C_u C l , C u 算法输出: 未标记样本的预测结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { − 1 , + 1 } , i = l + 1 , l + 2 , ⋯ , N \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T},\hat y_i \in \{-1,+1\},i=l+1,l+2,\cdots,N y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { − 1 , + 1 } , i = l + 1 , l + 2 , ⋯ , N
算法步骤:
用 D l \mathbb D_l D l SVM_l
用 SVM_l 对 D u \mathbb D_u D u y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T} y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T
初始化 C ~ u \tilde C_u C ~ u C ~ u ≪ C u , C ~ u > 0 \tilde C_u \ll C_u,\tilde C_u \gt 0 C ~ u ≪ C u , C ~ u > 0
迭代,迭代终止条件为 C ~ u ≥ C u \tilde C_u \ge C_u C ~ u ≥ C u
基于 D l , D u , y ⃗ ^ , C l , C ~ u \mathbb D_l,\mathbb D_u,\hat{\mathbf{\vec y}},C_l,\tilde C_u D l , D u , y ^ , C l , C ~ u ( w ⃗ , b ) , ξ ⃗ (\mathbf{\vec w},b),\vec \xi ( w , b ) , ξ
min w ⃗ , b , y ⃗ ^ , ξ ⃗ 1 2 ∣ ∣ w ⃗ ∣ ∣ 2 2 + C l ∑ i = 1 l ξ i + C ~ u ∑ i = l + 1 N ξ i s . t . y i ( w ⃗ T x ⃗ i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , l y ^ i ( w ⃗ T x ⃗ i + b ) ≥ 1 − ξ i , i = l + 1 , l + 2 , ⋯ , N ξ i ≥ 0 , i = 1 , 2 , ⋯ , N \min_{\mathbf{\vec w},b,\hat{\mathbf{\vec y}},\vec\xi} \frac 12 ||\mathbf{\vec w}||_2^{2}+C_l\sum_{i=1}^{l}\xi_i+\tilde C_u\sum_{i=l+1}^{N}\xi_i\\ s.t.\; y_i(\mathbf{\vec w}^{T}\mathbf{\vec x}_i+b) \ge 1-\xi_i,\quad i=1,2,\cdots,l\\ \hat y_i(\mathbf{\vec w}^{T}\mathbf{\vec x}_i+b) \ge 1-\xi_i,\quad i=l+1,l+2,\cdots,N\\ \xi_i \ge 0,\quad i=1,2,\cdots,N w , b , y ^ , ξ min 2 1 ∣∣ w ∣ ∣ 2 2 + C l i = 1 ∑ l ξ i + C ~ u i = l + 1 ∑ N ξ i s . t . y i ( w T x i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , l y ^ i ( w T x i + b ) ≥ 1 − ξ i , i = l + 1 , l + 2 , ⋯ , N ξ i ≥ 0 , i = 1 , 2 , ⋯ , N
对于所有的一对标记指派为异类且很可能发生错误的未标记样本(其条件为:y ^ i y ^ j < 0 and ξ i > 0 and ξ j > 0 and ξ i + ξ j > 2 \hat y_i\hat y_j \lt 0 \;\text{and}\; \xi_i \gt 0\;\text{and}\; \xi_j \gt 0 \;\text{and}\; \xi_i+\xi_j \gt 2 y ^ i y ^ j < 0 and ξ i > 0 and ξ j > 0 and ξ i + ξ j > 2
交换二者的标记:y ^ i = − y ^ i , y ^ j = − y ^ j \hat y_i=-\hat y_i,\quad \hat y_j=-\hat y_j y ^ i = − y ^ i , y ^ j = − y ^ j
该操作等价于交换标记,因为 y ^ i y ^ j \hat y_i\hat y_j y ^ i y ^ j
基于 D l , D u , y ⃗ ^ , C l , C ~ u \mathbb D_l,\mathbb D_u,\hat{\mathbf{\vec y}},C_l,\tilde C_u D l , D u , y ^ , C l , C ~ u ( w ⃗ , b ) , ξ ⃗ (\mathbf{\vec w},b),\vec \xi ( w , b ) , ξ
更新 C ~ u = min ( 2 C ~ u , C u , ) \tilde C_u= \min(2\tilde C_u,C_u,) C ~ u = min ( 2 C ~ u , C u , )
迭代终止时,输出 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T} y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T
在对未标记样本进行指标指派及调整的过程中,有可能出现类别不平衡问题,即某类的样本远多于另一类。这将对SVM的训练造成困扰。
为了减轻类别不平衡性造成的不利影响,可对上述算法稍加改进:将优化目标中的 C u C_u C u C u + C_u^{+} C u + C u − C_u^{- } C u −
C u + = u − u + C u − C_u^{+}=\frac{u_-}{u_+}C_u^{- } C u + = u + u − C u −
其中 u − u_- u − u + u_+ u +
性质 TSVM 最终得到的SVM 不仅可以给未标记样本提供了标记,还能对训练过程中未见的样本进行预测。
在 TSVM 算法中,寻找标记指派可能出错的每一对未标记样本进行调整,这是一个涉及巨大计算开销的大规模优化问题。
在论文《Large Scale Transductive SVMs》 中,约 2000 个未标记样本,原始TVSM 迭代收敛大约需要 1 个小时。 半监督SVM研究的一个重点是如何设计出高效的优化求解策略。由此发展成很多方法,如基于图核函数梯度下降的LDS算法,基于标记均值估计的meanS3VM算法等。
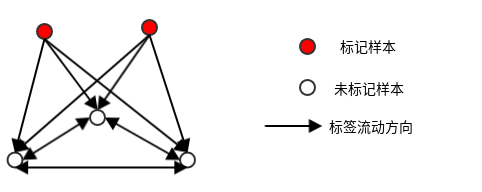
图半监督学习 标签传播算法 给定一个数据集,可以将其映射为一个图,数据集中每个样本对应于图中的一个结点。若两个样本之间的相似度很高(或者相关性很强),则对应的结点之间存在一条边,边的强度正比于样本之间的相似度(或相关性)。
将有标记样本所对应的结点视作为已经染色,而未标记样本所对应的结点尚未染色。于是半监督学习就对应于 “颜色” 在图上扩散或者传播的过程。这就是标记传播算法label propagation 。
给定标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } , y i ∈ { − 1 , + 1 } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\},y_i\in \{-1,+1\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} , y i ∈ { − 1 , + 1 } D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \} D u = { x l + 1 , x l + 2 , ⋯ , x l + u } l ≪ u , l + u = N l \ll u,\quad l+u=N l ≪ u , l + u = N
基于 D l ⋃ D u \mathbb D_l \bigcup \mathbb D_u D l ⋃ D u G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E )
结点集 V = { x ⃗ 1 , x ⃗ 2 , ⋯ , x ⃗ l , x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb V=\{\mathbf{\vec x}_1,\mathbf{\vec x}_2,\cdots,\mathbf{\vec x}_l, \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u}\} V = { x 1 , x 2 , ⋯ , x l , x l + 1 , x l + 2 , ⋯ , x l + u }
边集 E \mathbb E E affinity matirx W = ( w i , j ) N × N \mathbf W=(w_{i,j})_{N\times N} W = ( w i , j ) N × N
w i , j = { exp ( − ∣ ∣ x ⃗ i − x ⃗ j ∣ ∣ 2 2 2 σ 2 ) , i ≠ j 0 , i = j , i , j ∈ { 1 , 2 , ⋯ , N } w_{i,j}=\begin{cases} \exp\left(-\frac{||\mathbf{\vec x}_i-\mathbf{\vec x}_j||_2^{2}}{2\sigma^{2}}\right),& i \ne j\\ 0,&i=j \end{cases},\quad i,j\in \{1,2,\cdots,N\} w i , j = { exp ( − 2 σ 2 ∣∣ x i − x j ∣ ∣ 2 2 ) , 0 , i = j i = j , i , j ∈ { 1 , 2 , ⋯ , N }
其中 σ > 0 \sigma \gt 0 σ > 0
可以看到:
w i , j = w j , i w_{i,j}=w_{j,i} w i , j = w j , i W \mathbf W W 图 G \mathcal G G 两个点的距离越近,说明两个样本越相似,则边的权重越大;距离越远,说明两个样本越不相似,则边的权重越小。 权重越大说明样本越相似,则标签越容易传播。 能量函数 假定从图 G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E ) f : V → R f:\mathbb V\rightarrow \mathbb R f : V → R y i = sign ( f ( x ⃗ i ) ) , y i ∈ { − 1 , + 1 } y_i=\text{sign}(f(\mathbf{\vec x}_i)), y_i \in \{-1,+1\} y i = sign ( f ( x i )) , y i ∈ { − 1 , + 1 }
直观上看,相似的样本应该具有相似的标记,于是可以定义关于 f f f energy function:
E ( f ) = 1 2 ∑ i = 1 N ∑ j = 1 N w i , j ( f ( x ⃗ i ) − f ( x ⃗ j ) ) 2 = 1 2 ∑ i = 1 N ∑ j = 1 N [ w i , j f ( x ⃗ i ) 2 + w i , j f ( x ⃗ j ) 2 − 2 w i , j f ( x ⃗ i ) f ( x ⃗ j ) ] = 1 2 [ ∑ i = 1 N ( f ( x ⃗ i ) 2 ∑ j = 1 N w i , j ) + ∑ j = 1 N ( f ( x ⃗ j ) 2 ∑ i = 1 N w i , j ) − 2 ∑ i = 1 N ∑ j = 1 N w i , j f ( x ⃗ i ) f ( x ⃗ j ) ] E(f)=\frac 12 \sum_{i=1}^{N}\sum_{j=1}^{N}w_{i,j}\left(f(\mathbf{\vec x}_i)-f(\mathbf{\vec x}_j)\right)^{2}\\ =\frac 12 \sum_{i=1}^{N}\sum_{j=1}^{N} \left[w_{i,j}f(\mathbf{\vec x}_i)^{2}+w_{i,j}f(\mathbf{\vec x}_j)^{2}-2w_{i,j}f(\mathbf{\vec x}_i)f(\mathbf{\vec x}_j)\right]\\ = \frac 12\left[\sum_{i=1}^{N}\left(f(\mathbf{\vec x}_i)^{2}\sum_{j=1}^{N}w_{i,j}\right)+\sum_{j=1}^{N}\left(f(\mathbf{\vec x}_j)^{2}\sum_{i=1}^{N}w_{i,j}\right)-2\sum_{i=1}^{N}\sum_{j=1}^{N}w_{i,j}f(\mathbf{\vec x}_i)f(\mathbf{\vec x}_j)\right] E ( f ) = 2 1 i = 1 ∑ N j = 1 ∑ N w i , j ( f ( x i ) − f ( x j ) ) 2 = 2 1 i = 1 ∑ N j = 1 ∑ N [ w i , j f ( x i ) 2 + w i , j f ( x j ) 2 − 2 w i , j f ( x i ) f ( x j ) ] = 2 1 [ i = 1 ∑ N ( f ( x i ) 2 j = 1 ∑ N w i , j ) + j = 1 ∑ N ( f ( x j ) 2 i = 1 ∑ N w i , j ) − 2 i = 1 ∑ N j = 1 ∑ N w i , j f ( x i ) f ( x j ) ]
两个点距离越远, ( f ( x ⃗ i ) − f ( x ⃗ j ) ) 2 (f(\mathbf{\vec x}_i)-f(\mathbf{\vec x}_j))^{2} ( f ( x i ) − f ( x j ) ) 2 w i , j w_{i,j} w i , j w i , j ( f ( x ⃗ i ) − f ( x ⃗ j ) ) 2 w_{i,j}\left(f(\mathbf{\vec x}_i)-f(\mathbf{\vec x}_j)\right)^{2} w i , j ( f ( x i ) − f ( x j ) ) 2
因此能量函数 E ( f ) E(f) E ( f )
标签传播算法假定系统能量最小,即 E ( f ) E(f) E ( f )
考虑到E ( f ) E(f) E ( f ) w w , j w_{w,j} w w , j 距离较近的样本具有相近的输出 。
定义对角矩阵 D = diag ( d 1 , d 2 , ⋯ , d N ) \mathbf D=\text{diag}(d_1,d_2,\cdots,d_N) D = diag ( d 1 , d 2 , ⋯ , d N ) d i = ∑ j = 1 N w i , j d_i=\sum_{j=1}^{N}w_{i,j} d i = ∑ j = 1 N w i , j W \mathbf W W i i i
d i d_i d i i i i D \mathbf D D
D = [ d 1 0 0 ⋯ 0 0 d 2 0 ⋯ 0 0 0 d 3 ⋯ 0 ⋮ ⋮ ⋮ ⋱ ⋮ 0 0 0 ⋯ d N ] \mathbf D=\begin{bmatrix} d_1&0&0&\cdots&0\\ 0&d_2&0&\cdots&0\\ 0&0&d_3&\cdots&0\\ \vdots&\vdots&\vdots&\ddots&\vdots\\ 0&0&0&\cdots&d_N\\ \end{bmatrix} D = ⎣ ⎡ d 1 0 0 ⋮ 0 0 d 2 0 ⋮ 0 0 0 d 3 ⋮ 0 ⋯ ⋯ ⋯ ⋱ ⋯ 0 0 0 ⋮ d N ⎦ ⎤
定义 f ⃗ = ( f ( x ⃗ 1 ) , ⋯ , f ( x ⃗ l ) , f ( x ⃗ l + 1 ) , ⋯ , f ( x ⃗ N ) ) T \mathbf{\vec f}=(f(\mathbf{\vec x}_1),\cdots,f(\mathbf{\vec x}_l),f(\mathbf{\vec x}_{l+1}) ,\cdots,f(\mathbf{\vec x}_{N}))^{T} f = ( f ( x 1 ) , ⋯ , f ( x l ) , f ( x l + 1 ) , ⋯ , f ( x N ) ) T f f f
f ⃗ l = ( f ( x ⃗ 1 ) , f ( x ⃗ 2 ) , ⋯ , f ( x ⃗ l ) ) T \mathbf{\vec f}_l=(f(\mathbf{\vec x}_1),f(\mathbf{\vec x}_2),\cdots,f(\mathbf{\vec x}_l))^{T} f l = ( f ( x 1 ) , f ( x 2 ) , ⋯ , f ( x l ) ) T f f f f ⃗ u = ( f ( x ⃗ l + 1 ) , f ( x ⃗ l + 2 ) , ⋯ , f ( x ⃗ l + u ) ) T \mathbf{\vec f}_u=(f(\mathbf{\vec x}_{l+1}) ,f(\mathbf{\vec x}_{l+2}),\cdots,f(\mathbf{\vec x}_{l+u}))^{T} f u = ( f ( x l + 1 ) , f ( x l + 2 ) , ⋯ , f ( x l + u ) ) T f f f 结合 D \mathbf D D W \mathbf W W
E ( f ) = 1 2 [ ∑ i = 1 N f ( x ⃗ i ) 2 d i + ∑ j = 1 N f ( x ⃗ j ) 2 d j − 2 ∑ i = 1 N ∑ j = 1 N w i , j f ( x ⃗ i ) f ( x ⃗ j ) ] = ∑ i = 1 N f ( x ⃗ i ) 2 d i − ∑ i = 1 N ∑ j = 1 N w i , j f ( x ⃗ i ) f ( x ⃗ j ) = f ⃗ T ( D − W ) f ⃗ E(f)=\frac 12\left[\sum_{i=1}^{N} f(\mathbf{\vec x}_i)^{2}d_i +\sum_{j=1}^{N} f(\mathbf{\vec x}_j)^{2}d_j -2\sum_{i=1}^{N}\sum_{j=1}^{N}w_{i,j}f(\mathbf{\vec x}_i)f(\mathbf{\vec x}_j)\right]\\ = \sum_{i=1}^{N} f(\mathbf{\vec x}_i)^{2}d_i-\sum_{i=1}^{N}\sum_{j=1}^{N}w_{i,j}f(\mathbf{\vec x}_i)f(\mathbf{\vec x}_j) = \mathbf{\vec f}^{T}(\mathbf D-\mathbf W)\mathbf{\vec f} E ( f ) = 2 1 [ i = 1 ∑ N f ( x i ) 2 d i + j = 1 ∑ N f ( x j ) 2 d j − 2 i = 1 ∑ N j = 1 ∑ N w i , j f ( x i ) f ( x j ) ] = i = 1 ∑ N f ( x i ) 2 d i − i = 1 ∑ N j = 1 ∑ N w i , j f ( x i ) f ( x j ) = f T ( D − W ) f
标签传播算法将样本 x ⃗ \mathbf{\vec x} x f ( x ⃗ ) f(\mathbf{\vec x}) f ( x )
有标记样本的能量是已知的,未标记样本的能量是未知的。
能量在样本之间流动。对于样本 x ⃗ i \mathbf{\vec x}_i x i x ⃗ j \mathbf{\vec x}_j x j w i , j f ( x ⃗ j ) w_{i,j}f(\mathbf{\vec x}_j) w i , j f ( x j )
w i , j w_{i,j} w i , j 流出的能量可正可负,因为 f ( x ⃗ ) ∈ { 1 , − 1 } f(\mathbf{\vec x})\in\{1,-1\} f ( x ) ∈ { 1 , − 1 } 注意:能量不能在有标记样本与有标记样本之间流动,也不能从未标记样本流向有标记样本。 流经每个未标记样本的能量是守恒的。对未标记样本x ⃗ i , i = l + 1 , ⋯ , N \mathbf{\vec x}_i,i=l+1,\cdots,N x i , i = l + 1 , ⋯ , N
其能量流向其它的所有未标记结点 ,能量流出为:∑ j = l + 1 N w i , j f ( x ⃗ j ) \sum_{j=l+1}^N w_{i,j} f(\mathbf{\vec x}_j) ∑ j = l + 1 N w i , j f ( x j ) 其它所有结点(包括有标记样本 )都向其汇入能量,能量流入为:∑ j = 1 N w j , i f ( x ⃗ i ) \sum_{j=1}^N w_{j,i}f(\mathbf{\vec x}_i) ∑ j = 1 N w j , i f ( x i ) 考虑到 w i , j = w j , i w_{i,j}=w_{j,i} w i , j = w j , i d i = ∑ j = 1 N w i , j d_i=\sum_{j=1}^N w_{i,j} d i = ∑ j = 1 N w i , j d i f ( x ⃗ i ) = ∑ j = l + 1 N w i , j f ( x ⃗ j ) d_if(\mathbf{\vec x}_i) =\sum_{j=l+1}^Nw_{i,j}f(\mathbf{\vec x}_j) d i f ( x i ) = ∑ j = l + 1 N w i , j f ( x j )
从每个有标记样本流出的能量也是守恒的。对于有标记样本x ⃗ i , i = 1 , ⋯ , l \mathbf{\vec x}_i,i=1,\cdots,l x i , i = 1 , ⋯ , l 仅仅流出到未标记样本 ,因此流出能量为:∑ j = 1 l w i , j f ( x ⃗ j ) \sum_{j=1}^l w_{i,j} f(\mathbf{\vec x}_j) ∑ j = 1 l w i , j f ( x j )
由于有标记样本只有能量流出,没有能量流入,因此有:∑ j = 1 l w i , j f ( x ⃗ j ) = 0 \sum_{j=1}^l w_{i,j} f(\mathbf{\vec x}_j)=0 ∑ j = 1 l w i , j f ( x j ) = 0
综合两种能量守恒的情况,有:
D × [ 0 ⋮ 0 f ( x ⃗ l + 1 ) ⋮ f ( x ⃗ N ) ] = W × [ 0 ⋮ 0 f ( x ⃗ l + 1 ) ⋮ f ( x ⃗ N ) ] \mathbf D \times \begin{bmatrix} 0\\ \vdots\\ 0\\ f(\mathbf{\vec x}_{l+1})\\ \vdots\\ f(\mathbf{\vec x}_{N})\\ \end{bmatrix}= \mathbf W \times \begin{bmatrix} 0\\ \vdots\\ 0\\ f(\mathbf{\vec x}_{l+1})\\ \vdots\\ f(\mathbf{\vec x}_{N})\\ \end{bmatrix} D × ⎣ ⎡ 0 ⋮ 0 f ( x l + 1 ) ⋮ f ( x N ) ⎦ ⎤ = W × ⎣ ⎡ 0 ⋮ 0 f ( x l + 1 ) ⋮ f ( x N ) ⎦ ⎤
即有:( D − W ) ( 0 , ⋯ , 0 , f ( x ⃗ l + 1 ) , ⋯ , f ( x ⃗ N ) ) T = 0 ⃗ (\mathbf D-\mathbf W)(0,\cdots,0,f(\mathbf{\vec x}_{l+1}) ,\cdots,f(\mathbf{\vec x}_{N}))^{T}=\mathbf{\vec 0} ( D − W ) ( 0 , ⋯ , 0 , f ( x l + 1 ) , ⋯ , f ( x N ) ) T = 0
标签传播算法假定在满足约束条件的条件下,能量函数 E ( f ) E(f) E ( f )
标记约束:函数 f f f f ( x ⃗ i ) = y i , i = 1 , 2 , ⋯ , l f(\mathbf{\vec x}_i)=y_i,i=1,2,\cdots,l f ( x i ) = y i , i = 1 , 2 , ⋯ , l 能量守恒:定义拉普拉斯矩阵 L = D − W \mathbf L=\mathbf D-\mathbf W L = D − W L ( 0 , ⋯ , 0 , f ( x ⃗ l + 1 ) , ⋯ , f ( x ⃗ N ) ) T = 0 ⃗ \mathbf L(0,\cdots,0,f(\mathbf{\vec x}_{l+1}) ,\cdots,f(\mathbf{\vec x}_{N}))^{T}=\mathbf{\vec 0} L ( 0 , ⋯ , 0 , f ( x l + 1 ) , ⋯ , f ( x N ) ) T = 0 因此标签传播算法就是求解约束最优化问题:
min f E ( f ) s . t . f ( x ⃗ i ) = y i , i = 1 , 2 , ⋯ , l ( D − W ) ( 0 , ⋯ , 0 , f ( x ⃗ l + 1 ) , ⋯ , f ( x ⃗ N ) ) T = 0 ⃗ \min_fE(f)\\ s.t.\quad f(\mathbf{\vec x}_i)=y_i,i=1,2,\cdots,l\\ (\mathbf D-\mathbf W)(0,\cdots,0,f(\mathbf{\vec x}_{l+1}) ,\cdots,f(\mathbf{\vec x}_{N}))^{T}=\mathbf{\vec 0} f min E ( f ) s . t . f ( x i ) = y i , i = 1 , 2 , ⋯ , l ( D − W ) ( 0 , ⋯ , 0 , f ( x l + 1 ) , ⋯ , f ( x N ) ) T = 0
最优化求解 以第 l l l l l l
W = [ W l , l W l , u W u , l W u , u ] , D = [ D l , l 0 l , u 0 u , l D u , u ] \mathbf W=\begin{bmatrix} \mathbf W_{l,l}&\mathbf W_{l,u}\\ \mathbf W_{u,l}&\mathbf W_{u,u} \end{bmatrix},\quad \mathbf D=\begin{bmatrix} \mathbf D_{l,l}&\mathbf 0_{l,u}\\ \mathbf 0_{u,l}&\mathbf D_{u,u} \end{bmatrix} W = [ W l , l W u , l W l , u W u , u ] , D = [ D l , l 0 u , l 0 l , u D u , u ]
则:
E ( f ) = f ⃗ T ( D − W ) f ⃗ = ( f ⃗ l T f ⃗ u T ) ( [ D l , l 0 l , u 0 u , l D u , u ] − [ W l , l W l , u W u , l W u , u ] ) [ f ⃗ l f ⃗ u ] = f ⃗ l T ( D l , l − W l , l ) f ⃗ l − 2 f ⃗ u T W u , l f ⃗ l T + f ⃗ u T ( D u , u − W u , u ) f ⃗ u E(f)= \mathbf{\vec f}^{T}(\mathbf D-\mathbf W)\mathbf{\vec f} =(\mathbf{\vec f}_l^{T}\quad \mathbf{\vec f}_u^{T} )\left( \begin{bmatrix} \mathbf D_{l,l}&\mathbf 0_{l,u}\\ \mathbf 0_{u,l}&\mathbf D_{u,u} \end{bmatrix}- \begin{bmatrix} \mathbf W_{l,l}&\mathbf W_{l,u}\\ \mathbf W_{u,l}&\mathbf W_{u,u} \end{bmatrix} \right)\begin{bmatrix}\mathbf{\vec f}_l\\ \mathbf{\vec f}_u\end{bmatrix}\\ =\mathbf{\vec f}_l^{T}(\mathbf D_{l,l}-\mathbf W_{l,l})\mathbf{\vec f}_l-2\mathbf{\vec f}_u^{T} \mathbf W_{u,l}\mathbf{\vec f}_l^{T}+\mathbf{\vec f}_u^{T}(\mathbf D_{u,u}-\mathbf W_{u,u})\mathbf{\vec f}_u E ( f ) = f T ( D − W ) f = ( f l T f u T ) ( [ D l , l 0 u , l 0 l , u D u , u ] − [ W l , l W u , l W l , u W u , u ] ) [ f l f u ] = f l T ( D l , l − W l , l ) f l − 2 f u T W u , l f l T + f u T ( D u , u − W u , u ) f u
考虑到 f ⃗ l \mathbf{\vec f}_l f l E ( f ) E(f) E ( f ) f ⃗ u \mathbf{\vec f}_u f u E ( f ) E(f) E ( f ) ∂ E ( f ) ∂ f ⃗ u = 0 ⃗ \frac{\partial E(f)}{\partial \mathbf{\vec f}_u}=\mathbf{\vec 0} ∂ f u ∂ E ( f ) = 0
f ⃗ u = ( D u , u − W u , u ) − 1 W u , l f ⃗ l \mathbf{\vec f}_u=(\mathbf D_{u,u}-\mathbf W_{u,u})^{-1}\mathbf W_{u,l}\mathbf{\vec f}_l f u = ( D u , u − W u , u ) − 1 W u , l f l
令:
P = D − 1 W = [ D l , l − 1 0 l , u 0 u , l D u , u − 1 ] [ W l , l W l , u W u , l W u , u ] = [ D l , l − 1 W l , l D l , l − 1 W l , u D u , u − 1 W u , l D u , u − 1 W u , u ] \mathbf P=\mathbf D^{-1}\mathbf W=\begin{bmatrix} \mathbf D_{l,l}^{-1}&\mathbf 0_{l,u}\\ \mathbf 0_{u,l}&\mathbf D_{u,u}^{-1} \end{bmatrix}\begin{bmatrix} \mathbf W_{l,l}&\mathbf W_{l,u}\\ \mathbf W_{u,l}&\mathbf W_{u,u} \end{bmatrix} =\begin{bmatrix} \mathbf D_{l,l}^{-1}\mathbf W_{l,l}&\mathbf D_{l,l}^{-1}\mathbf W_{l,u}\\ \mathbf D_{u,u}^{-1}\mathbf W_{u,l}&\mathbf D_{u,u}^{-1}\mathbf W_{u,u} \end{bmatrix} P = D − 1 W = [ D l , l − 1 0 u , l 0 l , u D u , u − 1 ] [ W l , l W u , l W l , u W u , u ] = [ D l , l − 1 W l , l D u , u − 1 W u , l D l , l − 1 W l , u D u , u − 1 W u , u ]
令: P u , u = D u , u − 1 W u , u , P u , l = D u , u − 1 W u , l \mathbf P_{u,u}=\mathbf D_{u,u}^{-1}\mathbf W_{u,u},\quad \mathbf P_{u,l}=\mathbf D_{u,u}^{-1}\mathbf W_{u,l} P u , u = D u , u − 1 W u , u , P u , l = D u , u − 1 W u , l
f ⃗ u = ( D u , u − W u , u ) − 1 W u , l f ⃗ l = ( D u , u ( I − D u , u − 1 W u , u ) ) − 1 W u , l f ⃗ l = ( I − D u , u − 1 W u , u ) − 1 D u , u − 1 W u , l f ⃗ l = ( I − P u , u ) − 1 P u , l f ⃗ l \mathbf{\vec f}_u=(\mathbf D_{u,u}-\mathbf W_{u,u})^{-1}\mathbf W_{u,l}\mathbf{\vec f}_l\\ =(\mathbf D_{u,u}(\mathbf I-\mathbf D_{u,u}^{-1}\mathbf W_{u,u}))^{-1}\mathbf W_{u,l}\mathbf{\vec f}_l\\ = (\mathbf I-\mathbf D_{u,u}^{-1}\mathbf W_{u,u})^{-1}\mathbf D_{u,u}^{-1}\mathbf W_{u,l}\mathbf{\vec f}_l\\ =(\mathbf I-\mathbf P_{u,u})^{-1}\mathbf P_{u,l}\mathbf{\vec f}_l f u = ( D u , u − W u , u ) − 1 W u , l f l = ( D u , u ( I − D u , u − 1 W u , u ) ) − 1 W u , l f l = ( I − D u , u − 1 W u , u ) − 1 D u , u − 1 W u , l f l = ( I − P u , u ) − 1 P u , l f l
于是,将 D l \mathbb D_l D l f ⃗ l = ( y 1 , y 2 , ⋯ , y l ) T \mathbf{\vec f}_l=(y_1,y_2,\cdots,y_l)^{T} f l = ( y 1 , y 2 , ⋯ , y l ) T f ⃗ u \mathbf{\vec f}_u f u
P = ( p i , j ) N × N \mathbf P=(p_{i,j})_{N\times N} P = ( p i , j ) N × N
p i , j = w i , j d i = w i , j ∑ j = 1 N w i , j p_{i,j}=\frac{w_{i,j}}{d_i}=\frac{w_{i,j}}{\sum_{j=1}^{N}w_{i,j}} p i , j = d i w i , j = ∑ j = 1 N w i , j w i , j
它表示从节点 i i i j j j
注意到 w i , j d i ≠ w j , i d j \frac{w_{i,j}}{d_i} \ne \frac{w_{j,i}}{d_j} d i w i , j = d j w j , i P \mathbf P P 节点 i 转移到节点 j 的概率 不等于 节点i 转移到节点 j 的概率 。因此在Label Spreading 算法中,提出新的标记传播矩阵 S = D − 1 / 2 W D − 1 / 2 \mathbf S=\mathbf D^{-1 /2 }\mathbf W\mathbf D^{-1 /2} S = D − 1/2 W D − 1/2
S = [ w 1 , 1 d 1 w 1 , 2 d 1 × d 2 ⋯ w 1 , N d 1 × d N w 2 , 1 d 2 × d 1 w 2 , 2 d 2 ⋯ w 2 , N d 2 × d N ⋮ ⋮ ⋱ ⋮ w N , 1 d N × d 1 w N , 2 d N × d 2 ⋯ w N , N d N ] \mathbf S=\begin{bmatrix} \frac{w_{1,1}}{d_1}&\frac{w_{1,2}}{\sqrt{d_1\times d_2}}&\cdots &\frac{w_{1,N}}{\sqrt{d_1\times d_N}}\\ \frac{w_{2,1}}{\sqrt{d_2\times d_1}}&\frac{w_{2,2}}{d_2}&\cdots &\frac{w_{2,N}}{\sqrt{d_2\times d_N}}\\ \vdots&\vdots&\ddots &\vdots\\ \frac{w_{N,1}}{\sqrt{d_N\times d_1}}&\frac{w_{N,2}}{\sqrt{d_N\times d_2}}&\cdots &\frac{w_{N,N}}{d_N}\\ \end{bmatrix} S = ⎣ ⎡ d 1 w 1 , 1 d 2 × d 1 w 2 , 1 ⋮ d N × d 1 w N , 1 d 1 × d 2 w 1 , 2 d 2 w 2 , 2 ⋮ d N × d 2 w N , 2 ⋯ ⋯ ⋱ ⋯ d 1 × d N w 1 , N d 2 × d N w 2 , N ⋮ d N w N , N ⎦ ⎤
因此有:S = S T \mathbf S=\mathbf S^T S = S T 节点 i 转移到节点 j 的概率 等于 节点i 转移到节点 j 的概率 。此时的转移概率是非归一化的概率。
矩阵求逆 ( I − P u , u ) − 1 (\mathbf I-\mathbf P_{u,u})^{-1} ( I − P u , u ) − 1 O ( u 3 ) O(u^3) O ( u 3 ) u u u
首先执行初始化:f ⃗ < 0 > = ( y 1 , y 2 , ⋯ , y l , 0 , ⋯ , 0 ) T \mathbf{\vec f}^{<0>}=(y_1,y_2,\cdots,y_l,0,\cdots,0)^T f < 0 > = ( y 1 , y 2 , ⋯ , y l , 0 , ⋯ , 0 ) T
迭代过程:
执行标签传播:f ⃗ < t + 1 > = P f ⃗ < t > \mathbf{\vec f}^{<t+1>}=\mathbf P\mathbf{\vec f}^{<t>} f < t + 1 > = P f < t > 重置 f ⃗ \mathbf{\vec f} f f ⃗ l < t + 1 > = ( y 1 , y 2 , ⋯ , y l ) T \mathbf{\vec f}_l^{<t+1>}=(y_1,y_2,\cdots,y_l)^T f l < t + 1 > = ( y 1 , y 2 , ⋯ , y l ) T 还有一些没有讲的部分放在文末其他图半监督学习
半监督聚类 聚类是一种典型的无监督学习任务,然而在现实聚类任务中,往往能够获取一些额外的监督信息。于是可以通过半监督聚类semi-supervised clustering来利用监督信息以获取更好的聚类效果。
聚类任务中获得的监督信息大致有两种类型:
约束 k 均值算法 约束 k k k Constrained-k-means 是利用第一类监督信息的代表。
给定样本集 D = { x ⃗ 1 , x ⃗ 2 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\mathbf{\vec x}_2,\cdots,\mathbf{\vec x}_N\} D = { x 1 , x 2 , ⋯ , x N } M \mathcal M M C \mathcal C C
( x ⃗ i , x ⃗ j ) ∈ M (\mathbf{\vec x}_i,\mathbf{\vec x}_j) \in \mathcal M ( x i , x j ) ∈ M x ⃗ i \mathbf{\vec x}_i x i x ⃗ j \mathbf{\vec x}_j x j ( x ⃗ i , x ⃗ j ) ∈ C (\mathbf{\vec x}_i,\mathbf{\vec x}_j) \in \mathcal C ( x i , x j ) ∈ C x ⃗ i \mathbf{\vec x}_i x i x ⃗ j \mathbf{\vec x}_j x j 约束 k k k k k k M \mathcal M M C \mathcal C C
约束 k k k
输入:
D = { x ⃗ 1 , x ⃗ 2 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\mathbf{\vec x}_2,\cdots,\mathbf{\vec x}_N\} D = { x 1 , x 2 , ⋯ , x N } 必连关系集合 M \mathcal M M 勿连关系集合 C \mathcal C C 聚类簇数 K K K 输出:聚类簇划分 { C 1 , C 2 , ⋯ , C K } \{\mathbb C_1,\mathbb C_2,\cdots,\mathbb C_K\} { C 1 , C 2 , ⋯ , C K }
算法步骤:
从 D \mathbb D D K K K { μ ⃗ 1 , μ ⃗ 2 , ⋯ , μ ⃗ K } \{\vec \mu_1,\vec \mu_2,\cdots,\vec \mu_K\} { μ 1 , μ 2 , ⋯ , μ K }
迭代:
初始化每个簇 :C k = ϕ , k = 1 , 2 , ⋯ , K \mathbb C_k=\phi,k=1,2,\cdots,K C k = ϕ , k = 1 , 2 , ⋯ , K
对每个样本 x ⃗ i , i = 1 , 2 , ⋯ , N \mathbf{\vec x}_i,i=1,2,\cdots,N x i , i = 1 , 2 , ⋯ , N
初始化可选的簇的集合为 K = { 1 , 2 , ⋯ , K } \mathcal K=\{1,2,\cdots,K\} K = { 1 , 2 , ⋯ , K }
计算 x ⃗ i \mathbf{\vec x}_i x i d i , k = ∣ ∣ x ⃗ i − μ ⃗ k ∣ ∣ 2 2 , k = 1 , 2 , ⋯ , K d_{i,k}=||\mathbf{\vec x}_i-\vec \mu_k||_2^{2},k=1,2,\cdots,K d i , k = ∣∣ x i − μ k ∣ ∣ 2 2 , k = 1 , 2 , ⋯ , K
找出 k ∈ K k\in\mathcal K k ∈ K d i , k d_{i,k} d i , k k k k k = k ∗ k=k^{*} k = k ∗ d i , k ∗ d_{i,k^{*}} d i , k ∗ x ⃗ i \mathbf{\vec x}_i x i C k ∗ \mathbb C_{k^{*}} C k ∗ M \mathcal M M C \mathcal C C
若不违背,则 x ⃗ i \mathbf{\vec x}_i x i C k ∗ \mathbb C_{k^{*}} C k ∗ C k ∗ = C k ∗ ⋃ { x ⃗ i } \mathbb C_{k^{*}}=\mathbb C_{k^{*}}\bigcup \{\mathbf{\vec x}_i\} C k ∗ = C k ∗ ⋃ { x i }
若违背,则从 K \mathcal K K k ∗ k^{*} k ∗ k ∈ K k\in\mathcal K k ∈ K d i , k d_{i,k} d i , k k k k
重复上述考察,直到 K = ϕ \mathcal K=\phi K = ϕ x ⃗ i \mathbf{\vec x}_i x i C k ∗ \mathbb C_{k^{*}} C k ∗ M \mathcal M M C \mathcal C C
如果 K = ϕ \mathcal K=\phi K = ϕ x ⃗ i \mathbf{\vec x}_i x i
更新均值向量:
μ ⃗ k = 1 ∣ C k ∣ ∑ x ⃗ j ∈ C k x ⃗ j , k = 1 , 2 , ⋯ , K \vec\mu_k=\frac{1}{|\mathbb C_k|}\sum_{\mathbf{\vec x}_j\in \mathbb C_k}\mathbf{\vec x}_j,\quad k=1,2,\cdots,K μ k = ∣ C k ∣ 1 x j ∈ C k ∑ x j , k = 1 , 2 , ⋯ , K
若更新均值向量前后,均值向量变化很小,则迭代结束。 根据最新的均值向量划分 D \mathbb D D { C 1 , C 2 , ⋯ , C K } \{\mathbb C_1,\mathbb C_2,\cdots,\mathbb C_K\} { C 1 , C 2 , ⋯ , C K }
约束种子 k 均值算法 约束种子 k 均值Constrained Seed k-means算法是利用第二类监督的代表。
给定样本集 D = { x ⃗ 1 , x ⃗ 2 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\mathbf{\vec x}_2,\cdots,\mathbf{\vec x}_N\} D = { x 1 , x 2 , ⋯ , x N } S = ⋃ k = 1 K S k ⊂ D \mathbb S=\bigcup_{k=1}^{K}\mathbb S_k \subset \mathbb D S = ⋃ k = 1 K S k ⊂ D S k ≠ ϕ \mathbb S_k\ne \phi S k = ϕ k k k
直接将 S \mathbb S S K K K K K K k k k
约束种子 k k k
输入:
D = { x ⃗ 1 , x ⃗ 2 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\mathbf{\vec x}_2,\cdots,\mathbf{\vec x}_N\} D = { x 1 , x 2 , ⋯ , x N } 少量有标记样本 S = ⋃ k = 1 K S k ⊂ D \mathbb S=\bigcup_{k=1}^{K}\mathbb S_k \subset \mathbb D S = ⋃ k = 1 K S k ⊂ D 聚类簇数 K K K 输出:聚类簇划分 { C 1 , C 2 , ⋯ , C K } \{\mathbb C_1,\mathbb C_2,\cdots,\mathbb C_K\} { C 1 , C 2 , ⋯ , C K }
算法步骤:
利用有标记样本集合 S \mathbb S S μ ⃗ k = 1 ∣ S k ∣ ∑ x ⃗ i ∈ S k x ⃗ i , k = 1 , 2 , ⋯ , K \vec\mu_k=\frac {1}{|\mathbb S_k|}\sum_{\mathbf{\vec x}_i \in \mathbb S_k}\mathbf{\vec x}_i,\quad k=1,2,\cdots,K μ k = ∣ S k ∣ 1 x i ∈ S k ∑ x i , k = 1 , 2 , ⋯ , K
迭代:
初始化每个簇:C k = ϕ , k = 1 , 2 , ⋯ , K \mathbb C_k=\phi,k=1,2,\cdots,K C k = ϕ , k = 1 , 2 , ⋯ , K 将有标记样本集合 S \mathbb S S x ⃗ i \mathbf{\vec x}_i x i C k = C k ⋃ S k \mathbb C_k=\mathbb C_k\bigcup \mathbb S_k C k = C k ⋃ S k 对未标记样本集合 D − S \mathbb D-\mathbb S D − S x ⃗ i \mathbf{\vec x}_i x i 更新簇均值向量: μ ⃗ k = 1 ∣ C k ∣ ∑ x ⃗ j ∈ C k x ⃗ j , k = 1 , 2 , ⋯ , K \vec\mu_k=\frac {1}{|\mathbb C_k|}\sum_{\mathbf{\vec x}_j \in \mathbb C_k}\mathbf{\vec x}_j,\quad k=1,2,\cdots,K μ k = ∣ C k ∣ 1 x j ∈ C k ∑ x j , k = 1 , 2 , ⋯ , K
若更新均值向量前后,均值向量变化很小,则迭代结束。 根据最新的均值向量划分 D \mathbb D D { C 1 , C 2 , ⋯ , C K } \{\mathbb C_1,\mathbb C_2,\cdots,\mathbb C_K\} { C 1 , C 2 , ⋯ , C K }
总结 各种半监督学习算法的比较:
生成式半监督学习方法需要充分可靠的领域知识才能确保模型不至于太坏。 非监督SVM目标函数非凸,因此有不少工作致力于减轻非凸性造成的不利影响。 图半监督学习方法,图的质量极为重要。 基于分歧的方法将集成学习与半监督学习联系起来。 半监督学习在利用未标记样本后并非必然提升泛化性能,在有些情况下甚至会导致性能下降。
对生成式方法,原因通常是模型假设不准确。因此需要依赖充分可靠的领域知识来设计模型。
对半监督SVM,原因通常是训练数据中存在多个 “低密度划分”,而学习算法可能做出不利的选择。
S4VM通过优化最坏情况下性能来综合利用多个低密度划分,提升了此类技术的安全性。
更一般的安全半监督学习仍然是未决的难题。
安全是指:利用未标记样本后,能确保返回性能至少不差于仅利用有标记样本。
其他图半监督学习 多类标签传播算法 给定标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } , y i ∈ { 1 , 2 , ⋯ , K } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\},y_i\in \{1,2,\cdots,K\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} , y i ∈ { 1 , 2 , ⋯ , K } D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \} D u = { x l + 1 , x l + 2 , ⋯ , x l + u } l ≪ u , l + u = N l \ll u,\quad l+u=N l ≪ u , l + u = N
与二类标签传播算法一样,首先基于 D l ⋃ D u \mathbb D_l \bigcup\mathbb D_u D l ⋃ D u G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E ) W \mathbf W W D \mathbf D D
令 x ⃗ i \mathbf{\vec x}_i x i F ⃗ i = ( F i , 1 , F i , 2 , ⋯ , F i , K ) T \mathbf{\vec F}_i=(F_{i,1},F_{i,2},\cdots,F_{i,K})^{T} F i = ( F i , 1 , F i , 2 , ⋯ , F i , K ) T F i , k F_{i,k} F i , k x ⃗ i \mathbf{\vec x}_i x i k k k
∑ k = 1 K F i , k = 1 , F i , k ≥ 0 \sum_{k=1}^K F_{i,k}=1,\quad F_{i,k}\ge 0 k = 1 ∑ K F i , k = 1 , F i , k ≥ 0
对于标记样本 x ⃗ i \mathbf{\vec x}_i x i ( F i , 1 , F i , 2 , ⋯ , F i , K ) (F_{i,1},F_{i,2},\cdots,F_{i,K}) ( F i , 1 , F i , 2 , ⋯ , F i , K ) x ⃗ i \mathbf{\vec x}_i x i K ~ \tilde K K ~
F i , k = { 1 , k = K ~ 0 , k ! = K ~ F_{i,k}=\begin{cases} 1,& k=\tilde K\\ 0,& k!=\tilde K \end{cases} F i , k = { 1 , 0 , k = K ~ k ! = K ~
对于未标记样本 x ⃗ i \mathbf{\vec x}_i x i ( F i , 1 , F i , 2 , ⋯ , F i , K ) (F_{i,1},F_{i,2},\cdots,F_{i,K}) ( F i , 1 , F i , 2 , ⋯ , F i , K )
当给定 x ⃗ i \mathbf{\vec x}_i x i F ⃗ i \mathbf{\vec F}_i F i
y ^ i = arg max 1 ≤ j ≤ K F i , j \hat y_i=\arg\max_{1\le j \le K}F_{i,j} y ^ i = arg 1 ≤ j ≤ K max F i , j
其中 y ^ i \hat y_i y ^ i x ⃗ i \mathbf{\vec x}_i x i
定义非负的标记矩阵为: F = ( F ⃗ 1 , F ⃗ 2 , ⋯ , F ⃗ N ) T ∈ R N × K \mathbf F=(\mathbf{\vec F}_1,\mathbf{\vec F}_2,\cdots,\mathbf{\vec F}_N)^{T}\in \mathbb R^{N\times K} F = ( F 1 , F 2 , ⋯ , F N ) T ∈ R N × K
F = [ F 1 , 1 F 1 , 2 ⋯ F 1 , K F 2 , 1 F 2 , 2 ⋯ F 2 , K ⋮ ⋮ ⋱ ⋮ F N , 1 F N , 2 ⋯ F N , K ] \mathbf F=\begin{bmatrix} F_{1,1}&F_{1,2}&\cdots&F_{1,K}\\ F_{2,1}&F_{2,2}&\cdots&F_{2,K}\\ \vdots&\vdots&\ddots&\vdots\\ F_{N,1}&F_{N,2}&\cdots&F_{N,K}\\ \end{bmatrix} F = ⎣ ⎡ F 1 , 1 F 2 , 1 ⋮ F N , 1 F 1 , 2 F 2 , 2 ⋮ F N , 2 ⋯ ⋯ ⋱ ⋯ F 1 , K F 2 , K ⋮ F N , K ⎦ ⎤
即:F \mathbf F F F \mathbf F F soft label矩阵。
定义非负的常量矩阵 Y = ( Y i , j ) N × K \mathbf Y=(Y_{i,j})_{N\times K} Y = ( Y i , j ) N × K
Y i , j = { 1 , if 1 ≤ i ≤ l and y i = j 0 , otherwise Y_{i,j} =\begin{cases} 1,&\text{if}\quad 1 \le i\le l \quad \text{and} \quad y_i=j\\ 0,&\text{otherwise} \end{cases} Y i , j = { 1 , 0 , if 1 ≤ i ≤ l and y i = j otherwise
即:Y \mathbf Y Y l l l l l l u u u
Label Propagation Label Propagation 算法通过节点之间的边来传播标记,边的权重越大则表示两个节点越相似,则标记越容易传播。
定义概率转移矩阵 P = ( p i , j ) N × N \mathbf P=(p_{i,j})_{N\times N} P = ( p i , j ) N × N
p i , j = w i , j d i = w i , j ∑ j = 1 N w i , j p_{i,j}=\frac{w_{i,j}}{d_i}=\frac{w_{i,j}}{\sum_{j=1}^{N}w_{i,j}} p i , j = d i w i , j = ∑ j = 1 N w i , j w i , j
它表示标签从结点 i i i j j j
定义标记矩阵 Y l = ( Y i , j l ) l × K \mathbf Y_l=(Y_{i,j}^l)_{l\times K} Y l = ( Y i , j l ) l × K
Y i , j = { 1 , if y i = j 0 , otherwise Y_{i,j} =\begin{cases} 1,&\text{if} \quad y_i=j\\ 0,&\text{otherwise} \end{cases} Y i , j = { 1 , 0 , if y i = j otherwise
即:若 y i = k y_i=k y i = k i i i k k k
定义未标记矩阵 Y u = ( Y i , j u ) u × K \mathbf Y_u=(Y_{i,j}^u)_{u\times K} Y u = ( Y i , j u ) u × K i i i x ⃗ l + u \mathbf{\vec x}_{l+u} x l + u
合并 Y l \mathbf Y_l Y l Y u \mathbf Y_u Y u F \mathbf F F
Label Propagation 是个迭代算法。算法流程为:
Label Propatation 算法:
输入:
有标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } , y i ∈ { 1 , 2 , ⋯ , K } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\},y_i\in \{1,2,\cdots,K\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} , y i ∈ { 1 , 2 , ⋯ , K } 未标记样本集 D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } , l + u = N \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \},l+u=N D u = { x l + 1 , x l + 2 , ⋯ , x l + u } , l + u = N 构图参数 σ \sigma σ 输出:未标记样本的预测结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T},\hat y_i \in \{1,2,\cdots,K\},i=l+1,l+2,\cdots,l+u y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u
步骤:
w i , j = { exp ( − ∣ ∣ x ⃗ i − x ⃗ j ∣ ∣ 2 2 2 σ 2 ) , i ≠ j 0 , i = j , i , j ∈ { 1 , 2 , ⋯ , N } w_{i,j}=\begin{cases} \exp\left(-\frac{||\mathbf{\vec x}_i-\mathbf{\vec x}_j||_2^{2}}{2\sigma^{2}}\right),& i \ne j\\ 0,&i=j \end{cases},\quad i,j\in \{1,2,\cdots,N\} w i , j = { exp ( − 2 σ 2 ∣∣ x i − x j ∣ ∣ 2 2 ) , 0 , i = j i = j , i , j ∈ { 1 , 2 , ⋯ , N }
基于 W \mathbf W W P = D − 1 W \mathbf P=\mathbf D^{-1 }\mathbf W P = D − 1 W D − 1 = diag ( 1 d 1 , 1 d 2 , ⋯ , 1 d N ) \mathbf D^{-1}=\text{diag}(\frac 1 {d_1},\frac {1}{ {d_2}},\cdots,\frac {1}{ {d_N}}) D − 1 = diag ( d 1 1 , d 2 1 , ⋯ , d N 1 ) d i = ∑ j = 1 N w i , j d_i=\sum_{j=1}^{N}w_{i,j} d i = ∑ j = 1 N w i , j W \mathbf W W i i i
构造非负的常量矩阵 Y = ( Y i , j ) N × K \mathbf Y=(Y_{i,j})_{N\times K} Y = ( Y i , j ) N × K
Y i , j = { 1 , if 1 ≤ i ≤ l and y i = j 0 , otherwise Y_{i,j} =\begin{cases} 1,&\text{if}\quad 1 \le i\le l \quad \text{and} \quad y_i=j\\ 0,&\text{otherwise} \end{cases} Y i , j = { 1 , 0 , if 1 ≤ i ≤ l and y i = j otherwise
初始化 F < 0 > \mathbf F^{<0>} F < 0 > F < 0 > = Y \mathbf F^{<0>}=\mathbf Y F < 0 > = Y
初始化 t = 0 t=0 t = 0
迭代,迭代终止条件是 F \mathbf F F F ∗ \mathbf F^{*} F ∗
F < t + 1 > = P F < t > \mathbf F^{<t+1>}=\mathbf P\mathbf F^{<t>} F < t + 1 > = P F < t > F l < t + 1 > = Y l \mathbf F_l^{<t+1>}=\mathbf Y_l F l < t + 1 > = Y l F l \mathbf F_l F l F \mathbf F F l l l t = t + 1 t=t+1 t = t + 1 构造未标记样本的预测结果:
y ^ i = arg max j ∈ { 1 , 2 , ⋯ , K } F i , j ∗ , i = l + 1 , l + 2 , ⋯ , N \hat y_{i}=\arg\max_{j\in\{1,2,\cdots,K\}} F^{*}_{i,j} ,i=l+1,l+2,\cdots,N y ^ i = arg j ∈ { 1 , 2 , ⋯ , K } max F i , j ∗ , i = l + 1 , l + 2 , ⋯ , N
输出结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T} y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T Label Spreading Label Spreading 算法也是个迭代算法:
首先初始化 F \mathbf F F F < 0 > = Y \mathbf F^{<0>}=\mathbf Y F < 0 > = Y < 0 > <0> < 0 >
然后迭代:F < t + 1 > = α S F < t > + ( 1 − α ) Y \mathbf F^{<t+1>} =\alpha \mathbf S \mathbf F^{<t>} +(1-\alpha)\mathbf Y F < t + 1 > = α S F < t > + ( 1 − α ) Y
S \mathbf S S S = D − 1 / 2 W D − 1 / 2 \mathbf S=\mathbf D^{-1 /2 }\mathbf W\mathbf D^{-1 /2} S = D − 1/2 W D − 1/2 D − 1 / 2 = diag ( 1 d 1 , 1 d 2 , ⋯ , 1 d N ) \mathbf D^{-1 /2}=\text{diag}(\frac {1}{\sqrt{d_1}},\frac {1}{\sqrt{d_2}},\cdots,\frac {1}{\sqrt{d_N}}) D − 1/2 = diag ( d 1 1 , d 2 1 , ⋯ , d N 1 )
α ∈ ( 0 , 1 ) \alpha \in (0,1) α ∈ ( 0 , 1 ) S F < t > \mathbf S \mathbf F^{<t>} S F < t > Y \mathbf Y Y
α → 0 \alpha \rightarrow 0 α → 0 Y \mathbf Y Y Y \mathbf Y Y α → 1 \alpha \rightarrow 1 α → 1 Y \mathbf Y Y Y \mathbf Y Y 迭代直至收敛,可以得到:F ∗ = lim t → ∞ F < t > = ( 1 − α ) ( I − α S ) − 1 Y \mathbf F^{*}=\lim_{t\rightarrow \infty}\mathbf F^{<t>}=(1-\alpha)(\mathbf I-\alpha \mathbf S)^{-1}\mathbf Y F ∗ = lim t → ∞ F < t > = ( 1 − α ) ( I − α S ) − 1 Y F ∗ \mathbf F^{*} F ∗ D u \mathbb D_u D u
由于引入 α \alpha α Label Spreading 最终收敛的结果中,标记样本的标签可能会发生改变。这在一定程度上能对抗噪音的影响。
如:α = 0.2 \alpha=0.2 α = 0.2
Label Spreading算法:
输入:
有标记样本集 D l = { ( x ⃗ 1 , y 1 ) , ( x ⃗ 2 , y 2 ) , ⋯ , ( x ⃗ l , y l ) } , y i ∈ { 1 , 2 , ⋯ , K } \mathbb D_l=\{(\mathbf{\vec x}_1,y_1),(\mathbf{\vec x}_2,y_2),\cdots,(\mathbf{\vec x}_l,y_l)\},y_i\in \{1,2,\cdots,K\} D l = {( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x l , y l )} , y i ∈ { 1 , 2 , ⋯ , K }
未标记样本集 D u = { x ⃗ l + 1 , x ⃗ l + 2 , ⋯ , x ⃗ l + u } , l + u = N \mathbb D_u=\{ \mathbf{\vec x}_{l+1}, \mathbf{\vec x}_{l+2} ,\cdots, \mathbf{\vec x}_{l+u} \},l+u=N D u = { x l + 1 , x l + 2 , ⋯ , x l + u } , l + u = N
构图参数 σ \sigma σ
折中参数 α \alpha α
输出:未标记样本的预测结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T},\hat y_i \in \{1,2,\cdots,K\},i=l+1,l+2,\cdots,l+u y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T , y ^ i ∈ { 1 , 2 , ⋯ , K } , i = l + 1 , l + 2 , ⋯ , l + u
步骤:
w i , j = { exp ( − ∣ ∣ x ⃗ i − x ⃗ j ∣ ∣ 2 2 2 σ 2 ) , i ≠ j 0 , i = j , i , j ∈ { 1 , 2 , ⋯ , N } w_{i,j}=\begin{cases} \exp\left(-\frac{||\mathbf{\vec x}_i-\mathbf{\vec x}_j||_2^{2}}{2\sigma^{2}}\right),& i \ne j\\ 0,&i=j \end{cases},\quad i,j\in \{1,2,\cdots,N\} w i , j = { exp ( − 2 σ 2 ∣∣ x i − x j ∣ ∣ 2 2 ) , 0 , i = j i = j , i , j ∈ { 1 , 2 , ⋯ , N }
基于 W \mathbf W W S = D − 1 / 2 W D − 1 / 2 \mathbf S=\mathbf D^{-1 /2 }\mathbf W\mathbf D^{-1 /2} S = D − 1/2 W D − 1/2 D − 1 / 2 = diag ( 1 d 1 , 1 d 2 , ⋯ , 1 d N ) \mathbf D^{-1 /2}=\text{diag}(\frac {1}{\sqrt{d_1}},\frac {1}{\sqrt{d_2}},\cdots,\frac {1}{\sqrt{d_N}}) D − 1/2 = diag ( d 1 1 , d 2 1 , ⋯ , d N 1 ) d i = ∑ j = 1 N w i , j d_i=\sum_{j=1}^{N}w_{i,j} d i = ∑ j = 1 N w i , j W \mathbf W W i i i
构造非负的常量矩阵 Y = ( Y i , j ) N × K \mathbf Y=(Y_{i,j})_{N\times K} Y = ( Y i , j ) N × K
Y i , j = { 1 , if 1 ≤ i ≤ l and y i = j 0 , otherwise Y_{i,j} =\begin{cases} 1,&\text{if}\quad 1 \le i\le l \quad \text{and} \quad y_i=j\\ 0,&\text{otherwise} \end{cases} Y i , j = { 1 , 0 , if 1 ≤ i ≤ l and y i = j otherwise
初始化 F < 0 > \mathbf F^{<0>} F < 0 > F < 0 > = Y \mathbf F^{<0>}=\mathbf Y F < 0 > = Y
初始化 t = 0 t=0 t = 0
迭代,迭代终止条件是 F \mathbf F F F ∗ \mathbf F^{*} F ∗
F < t + 1 > = α S F < t > + ( 1 − α ) Y \mathbf F^{<t+1>} =\alpha \mathbf S \mathbf F^{<t>} +(1-\alpha)\mathbf Y F < t + 1 > = α S F < t > + ( 1 − α ) Y t = t + 1 t=t+1 t = t + 1 构造未标记样本的预测结果:
y ^ i = arg max j ∈ { 1 , 2 , ⋯ , K } F i , j ∗ , i = l + 1 , l + 2 , ⋯ , N \hat y_{i}=\arg\max_{j\in\{1,2,\cdots,K\}} F^{*}_{i,j} ,i=l+1,l+2,\cdots,N y ^ i = arg j ∈ { 1 , 2 , ⋯ , K } max F i , j ∗ , i = l + 1 , l + 2 , ⋯ , N
输出结果 y ⃗ ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T \hat{\mathbf{\vec y}}=(\hat y_{l+1},\hat y_{l+2},\cdots,\hat y_{l+u})^{T} y ^ = ( y ^ l + 1 , y ^ l + 2 , ⋯ , y ^ l + u ) T 性质 其实上述算法都对应于正则化框架:
min F 1 2 ( ∑ i = 1 N ∑ j = 1 N w i , j ∣ ∣ 1 d i F ⃗ i − 1 d j F ⃗ j ∣ ∣ 2 2 ) + μ ∑ i = 1 l ∣ ∣ F ⃗ i − Y ⃗ i ∣ ∣ 2 2 \min_{\mathbf F}\frac 12\left(\sum_{i=1}^{N}\sum_{j=1}^N w_{i,j}||\frac {1}{\sqrt{d_i}}\mathbf{\vec F}_i-\frac {1}{\sqrt{d_j}}\mathbf{\vec F}_j||_2^{2}\right)+\mu\sum_{i=1}^{l}|| \mathbf{\vec F}_i- \mathbf{\vec Y}_i||_2^{2} F min 2 1 ( i = 1 ∑ N j = 1 ∑ N w i , j ∣∣ d i 1 F i − d j 1 F j ∣ ∣ 2 2 ) + μ i = 1 ∑ l ∣∣ F i − Y i ∣ ∣ 2 2
其中:
μ > 0 \mu \gt 0 μ > 0 μ = 1 − α α \mu=\frac{1-\alpha}{\alpha} μ = α 1 − α F ∗ = ( 1 − α ) ( I − α S ) − 1 Y \mathbf F^{*}=(1-\alpha)(\mathbf I-\alpha \mathbf S)^{-1}\mathbf Y F ∗ = ( 1 − α ) ( I − α S ) − 1 Y 上式第二项:迫使学得结果在有标记样本上的预测与真实标记尽可能相同。 上式第一项:迫使相近样本具有相似的标记。 这里的标记既可以是离散的类别,也可以是连续的值。
虽然二类标签传播算法和多类标签传播算法理论上都收敛,而且都知道解析解。但是:
对二类标签传播算法,矩阵求逆 ( I − P u , u ) − 1 (\mathbf I-\mathbf P_{u,u})^{-1} ( I − P u , u ) − 1 O ( u 3 ) O(u^3) O ( u 3 ) u u u 对多类标签传播算法,矩阵求逆 ( I − α S ) − 1 (\mathbf I-\alpha \mathbf S)^{-1} ( I − α S ) − 1 O ( N 3 ) O(N^3) O ( N 3 ) N N N 因此标签传播算法一般选择迭代算法来实现。
图半监督学习方法在概念上相当清晰,且易于通过对所涉及矩阵运算的分析来探索算法性质。
缺点:
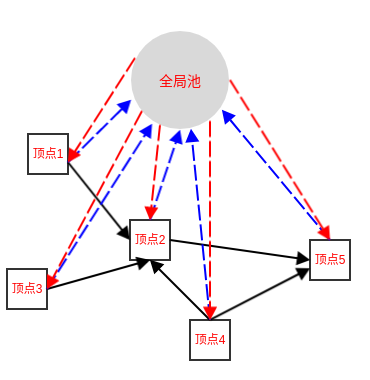
在存储开销上较大,使得此类算法很难直接处理大规模数据。 由于构图过程仅能考虑训练样本集,难以判断新的样本在图中的位置。因此在接收到新样本时,要么将其加入原数据集对图进行重构并重新进行标记传播,要么引入额外的预测机制。 PageRank 算法用于对网页进行排名。它也是利用能量在有向图 G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E )
每个网页代表图 G \mathcal G G V \mathbb V V
如果存在超链接,该超链接从顶点 i i i j j j i i i j j j
所有的边的集合为 E \mathbb E E
每个顶点都存储有能量,能量对应着网页的重要性得分。
对每个网页,设其能量为 y y y
用户以概率 1 − e 1-e 1 − e ( 1 − e ) × y (1-e)\times y ( 1 − e ) × y
用户以概率 e e e e × y e\times y e × y e × Total N \frac {e \times \text{Total}}N N e × Total Total \text{Total} Total N N N
这是因为每个顶点都有 e e e e × Total e\times \text{Total} e × Total e × Total N \frac {e \times \text{Total}}N N e × Total
当系统取得平衡时,满足以下条件:
全局能量池的流入、流出能量守恒。 每个顶点的流入、流出能量守恒。 系统所有顶点的总能量为常数。 假设 Total = 1 \text{Total}=1 Total = 1 i i i y i y_i y i
流出能量为: ( 1 − e ) × y i + e × y i (1-e)\times y_i+e\times y_i ( 1 − e ) × y i + e × y i 流入能量为:( 1 − e ) × ∑ j ≠ i y j p i , j + e N (1-e)\times \sum_{j\ne i}y_jp_{i,j} +\frac eN ( 1 − e ) × ∑ j = i y j p i , j + N e p i , j p_{i,j} p i , j j j j i i i 则顶点 i i i ( 1 − e ) × ∑ j ≠ i y j p j , i + e N − y i (1-e)\times \sum_{j\ne i}y_jp_{j,i}+\frac eN-y_i ( 1 − e ) × ∑ j = i y j p j , i + N e − y i
考虑所有顶点,令 y ⃗ = ( y 1 , ⋯ , y N ) T \mathbf {\vec y}=(y_1,\cdots,y_N)^T y = ( y 1 , ⋯ , y N ) T P = ( p i , j ) N × N \mathbf P=(p_{i,j})_{N\times N} P = ( p i , j ) N × N 1 ⃗ = ( 1 , 1 , ⋯ , 1 ) T \mathbf{\vec 1}=(1,1,\cdots,1)^T 1 = ( 1 , 1 , ⋯ , 1 ) T
( 1 − e ) P y ⃗ + e N 1 ⃗ − y ⃗ (1-e) \mathbf P\mathbf{\vec y} +\frac eN\mathbf{\vec 1}- \mathbf{\vec y} ( 1 − e ) P y + N e 1 − y
当系统稳定时,每个顶点的净流入能量为 0 。因此有:( 1 − e ) P y ⃗ + e N 1 ⃗ − y ⃗ = 0 ⃗ (1-e) \mathbf P\mathbf{\vec y} +\frac eN\mathbf{\vec 1}- \mathbf{\vec y}=\mathbf{\vec 0} ( 1 − e ) P y + N e 1 − y = 0
考虑到所有顶点的总能量恒定为 1,则有 ∑ i y i = 1 \sum_i y_i=1 ∑ i y i = 1
定义矩阵 T \mathbf T T
T = [ 1 1 ⋯ 1 1 1 ⋯ 1 ⋮ ⋮ ⋱ ⋮ 1 1 ⋯ 1 ] \mathbf T=\begin{bmatrix} 1&1&\cdots&1\\ 1&1&\cdots&1\\ \vdots&\vdots&\ddots&\vdots\\ 1&1&\cdots&1\\ \end{bmatrix} T = ⎣ ⎡ 1 1 ⋮ 1 1 1 ⋮ 1 ⋯ ⋯ ⋱ ⋯ 1 1 ⋮ 1 ⎦ ⎤
则有:T y ⃗ = 1 ⃗ \mathbf T\mathbf{\vec y}=\mathbf{\vec 1} T y = 1 [ ( 1 − e ) P + e N T ] y ⃗ = y ⃗ \left[(1-e)\mathbf P+\frac eN \mathbf T\right]\mathbf{\vec y} = \mathbf{\vec y} [ ( 1 − e ) P + N e T ] y = y
令 U = [ ( 1 − e ) P + e N T ] \mathbf U=\left[(1-e)\mathbf P+\frac eN \mathbf T\right] U = [ ( 1 − e ) P + N e T ] U y ⃗ = y ⃗ \mathbf U\mathbf{\vec y}=\mathbf{\vec y} U y = y y ⃗ \mathbf{\vec y} y U \mathbf U U
标签传播与社区发现 设图 G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E ) G \mathcal G G K K K C = { C 1 , ⋯ , C K } \mathcal C=\{\mathbb C_1,\cdots,\mathbb C_K\} C = { C 1 , ⋯ , C K } C 1 ⋃ ⋯ ⋃ C K = V \mathbb C_1\bigcup\cdots\bigcup\mathbb C_K=\mathbb V C 1 ⋃ ⋯ ⋃ C K = V
若任意两个社区的顶点集合的交集均为空,则称 C \mathcal C C
社区划分的好坏是通过考察当前图的社区划分,与随机图的社区划分的差异来衡量的。
当前图的社区划分:计算当前图的社区结构中,内部顶点的边占所有边的比例 :1 2 M ∑ i ∈ V ∑ j ∈ V w i , j δ ( c i , c j ) \frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} w_{i,j} \delta(c_i,c_j) 2 M 1 ∑ i ∈ V ∑ j ∈ V w i , j δ ( c i , c j )
其中:
w i , j w_{i,j} w i , j i i i j j j M M M G \mathcal G G M = 1 2 ∑ i ∈ V ∑ j ∈ V w i , j M=\frac 12 \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} w_{i,j} M = 2 1 ∑ i ∈ V ∑ j ∈ V w i , j
c i c_i c i i i i c j c_j c j j j j δ ( ⋅ , ⋅ ) \delta(\cdot,\cdot) δ ( ⋅ , ⋅ )
δ ( x , y ) = { 0 , x ≠ y 1 , x = y \delta(x,y)=\begin{cases} 0,& x\ne y\\ 1,& x=y \end{cases} δ ( x , y ) = { 0 , 1 , x = y x = y
因为 w i , j = w j , i w_{i,j}=w_{j,i} w i , j = w j , i 2 M 2M 2 M
它可以简化为: ∑ k = 1 K m k M \sum_{k=1}^K \frac{m_k}{M} ∑ k = 1 K M m k m k m_k m k C k \mathbb C_k C k
随机图的社区划分:计算随机图的社区结构中,内部顶点的边占所有边的比例的期望。
随机图是这样生成的:每个顶点的度保持不变,边重新连接。
记顶点 i i i j j j p i , j p_{i,j} p i , j
因为每个顶点的度不变,则最终总度数不变。即:∑ i ∈ V ∑ j ∈ V p i , j = 2 M \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} p_{i,j} = 2M ∑ i ∈ V ∑ j ∈ V p i , j = 2 M 对每个顶点,它的度保持不变。即:∑ j ∈ V p i , j = d i \sum_{j\in\mathbb V}p_{i,j}=d_i ∑ j ∈ V p i , j = d i d i d_i d i i i i 随机连边时,一个边的两个顶点的选择都是独立、随机的。因此对于 p i , j p_{i,j} p i , j i i i d i d_i d i j j j d j d_j d j p i , j = f ( d i ) f ( d j ) p_{i,j}=f(d_i)f(d_j) p i , j = f ( d i ) f ( d j ) f ( ⋅ ) f(\cdot) f ( ⋅ ) 根据 ∑ j ∈ V p i , j = d i \sum_{j\in\mathbb V}p_{i,j}=d_i ∑ j ∈ V p i , j = d i ∑ j ∈ V p i , j = f ( d i ) ∑ j ∈ V f ( d j ) \sum_{j\in\mathbb V}p_{i,j}=f(d_i)\sum_{j\in\mathbb V} f(d_j) ∑ j ∈ V p i , j = f ( d i ) ∑ j ∈ V f ( d j ) d i = f ( d i ) ∑ j ∈ V f ( d j ) d_i = f(d_i)\sum_{j\in\mathbb V} f(d_j) d i = f ( d i ) ∑ j ∈ V f ( d j )
由于 ∑ j ∈ V f ( d j ) \sum_{j\in\mathbb V} f(d_j) ∑ j ∈ V f ( d j ) d i d_i d i f ( d i ) f(d_i) f ( d i ) d i d_i d i f ( d i ) = T d i f(d_i)=T d_i f ( d i ) = T d i T T T
∑ i ∈ V ∑ j ∈ V p i , j = ∑ i ∈ V ∑ j ∈ V T 2 d i × d j = 2 M \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} p_{i,j}=\sum_{i\in \mathbb V}\sum_{j \in \mathbb V} T^2d_i\times d_j = 2M i ∈ V ∑ j ∈ V ∑ p i , j = i ∈ V ∑ j ∈ V ∑ T 2 d i × d j = 2 M
考虑到 ∑ i ∈ V d i = 2 M \sum_{i\in \mathbb V} d_i = 2M ∑ i ∈ V d i = 2 M ( 2 M ) 2 = ( ∑ i ∈ V d i ) 2 = ∑ i ∈ V ∑ j ∈ V d i × d j (2M)^2=\left(\sum_{i\in \mathbb V} d_i \right)^2=\sum_{i\in \mathbb V}\sum_{j \in \mathbb V} d_i\times d_j ( 2 M ) 2 = ( ∑ i ∈ V d i ) 2 = ∑ i ∈ V ∑ j ∈ V d i × d j
T 2 × ( 2 M ) 2 = 2 M T^2\times (2M)^2=2M T 2 × ( 2 M ) 2 = 2 M
因此有:p i , j = T 2 × d i × d j = d i × d j 2 M p_{i,j}=T^2\times d_i\times d_j=\frac {d_i\times d_j}{2M} p i , j = T 2 × d i × d j = 2 M d i × d j
因此随机图的社区结构中,内部顶点的边占所有边的比例的期望为:
1 2 M ∑ i ∈ V ∑ j ∈ V p i , j δ ( c i , c j ) = 1 2 M ∑ i ∈ V ∑ j ∈ V d i × d j 2 M δ ( c i , c j ) \frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} p_{i,j} \delta(c_i,c_j)=\frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V}\frac{d_i\times d_j}{2M} \delta(c_i,c_j) 2 M 1 i ∈ V ∑ j ∈ V ∑ p i , j δ ( c i , c j ) = 2 M 1 i ∈ V ∑ j ∈ V ∑ 2 M d i × d j δ ( c i , c j )
定义modularity 指标为 Q Q Q
Q = 1 2 M ∑ i ∈ V ∑ j ∈ V [ w i , j − d i × d j 2 M ] δ ( c i , c j ) Q=\frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} \left[w_{i,j} - \frac{d_i\times d_j}{2M}\right]\delta(c_i,c_j) Q = 2 M 1 i ∈ V ∑ j ∈ V ∑ [ w i , j − 2 M d i × d j ] δ ( c i , c j )
它就是:当前网络中连接社区结构内部顶点的边所占的比例,与另外一个随机网络中连接社区结构内部顶点的便所占比例的期望相减,得到的差值。用于刻画社区划分的好坏。
第一项:
1 2 M ∑ i ∈ V ∑ j ∈ V w i , j δ ( c i , c j ) = 1 2 M ∑ k = 1 K ∑ i ∈ C k ∑ j ∈ C k w i , j = ∑ k = 1 K 2 m k 2 M = ∑ k = 1 K m k M \frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} w_{i,j} \delta(c_i,c_j)=\frac {1}{2 M} \sum_{k=1}^K\sum_{i\in \mathbb C_k}\sum_{j\in \mathbb C_k} w_{i,j}\\ = \sum_{k=1}^K \frac{2m_k}{2M}=\sum_{k=1}^K \frac{m_k}{M} 2 M 1 i ∈ V ∑ j ∈ V ∑ w i , j δ ( c i , c j ) = 2 M 1 k = 1 ∑ K i ∈ C k ∑ j ∈ C k ∑ w i , j = k = 1 ∑ K 2 M 2 m k = k = 1 ∑ K M m k
第二项:
1 2 M ∑ i ∈ V ∑ j ∈ V d i × d j 2 M δ ( c i , c j ) = ∑ k = 1 K ∑ i ∈ C k ∑ j ∈ C k d i 2 M × d j 2 M = ∑ k = 1 K ( ∑ i ∈ C k d i 2 M ) 2 = ∑ k = 1 K ( D k 2 M ) 2 \frac {1}{2 M} \sum_{i\in \mathbb V}\sum_{j \in \mathbb V} \frac{d_i\times d_j}{2M}\delta(c_i,c_j)=\sum_{k=1}^K\sum_{i\in \mathbb C_k}\sum_{j\in \mathbb C_k} \frac{d_i}{2M}\times \frac{d_j}{2M}\\ =\sum_{k=1}^K\left( \frac{\sum_{i\in \mathbb C_k}d_i}{2M}\right)^2=\sum_{k=1}^K\left( \frac{D_k}{2M}\right)^2 2 M 1 i ∈ V ∑ j ∈ V ∑ 2 M d i × d j δ ( c i , c j ) = k = 1 ∑ K i ∈ C k ∑ j ∈ C k ∑ 2 M d i × 2 M d j = k = 1 ∑ K ( 2 M ∑ i ∈ C k d i ) 2 = k = 1 ∑ K ( 2 M D k ) 2
因此,经过化简之后为:
Q = ∑ k = 1 K ( m k M − ( D k 2 M ) 2 ) Q = \sum_{k=1}^K \left(\frac{m_k}{M}-\left(\frac{D_k}{2M}\right)^2\right) Q = k = 1 ∑ K ( M m k − ( 2 M D k ) 2 )
其中:
m k m_k m k C k \mathbb C_k C k m k = 1 2 ∑ i ∈ C k ∑ j ∈ C k w i , j m_k=\frac 12 \sum_{i\in \mathbb C_k}\sum_{j\in \mathbb C_k} w_{i,j} m k = 2 1 ∑ i ∈ C k ∑ j ∈ C k w i , j
D k D_k D k C k \mathbb C_k C k D i = ∑ i ∈ C k d i D_i=\sum_{i\in \mathbb C_k}d_i D i = ∑ i ∈ C k d i
D k 2 M \frac{D_k}{2M} 2 M D k C k \mathbb C_k C k D k D_k D k D k = 2 m k + O k D_k=2m_k + O_k D k = 2 m k + O k O k O_k O k C k \mathbb C_k C k Q Q Q (-1,1) 之间。
当社区之间不存在边的连接时, Q Q Q 当每个点都是一个社区时, Q Q Q Fast Unfolding Fast Unfolding 算法是基于modularity 的社区划分算法。
它是一种迭代算法,每一步 3 迭代的目标是:使得划分后整个网络的 modularity 不断增大。
Fast Unfolding 算法主要包括两个阶段:
第一阶段称作 modularity optimization:将每个顶点划分到与其邻接的顶点所在的社区中,以使得 modularity 不断增大。
考虑顶点 i i i j j j C k \mathbb C_k C k
未划分之前,顶点 i i i Q Q Q − ( d i 2 M ) 2 -\left(\frac{d_i}{2M}\right)^2 − ( 2 M d i ) 2 d i d_i d i
未划分之前,社区 C k \mathbb C_k C k Q Q Q m k M − ( D k 2 M ) 2 \frac{m_k}{M}-\left(\frac{D_k}{2M}\right)^2 M m k − ( 2 M D k ) 2
划分之后,除了社区 C k \mathbb C_k C k i i i Q Q Q
Δ Q = [ m k ′ M − ( D k ′ 2 M ) 2 ] − [ m k M − ( D k 2 M ) 2 − ( d i 2 M ) 2 ] \Delta Q=\left[\frac{m_k^\prime}{M}-\left(\frac{D_k^\prime}{2M}\right)^2\right]-\left[\frac{m_k}{M}-\left(\frac{D_k}{2M}\right)^2-\left(\frac{d_i}{2M}\right)^2\right] Δ Q = [ M m k ′ − ( 2 M D k ′ ) 2 ] − [ M m k − ( 2 M D k ) 2 − ( 2 M d i ) 2 ]
其中 m k ′ , D k ′ m_k^\prime, D_k^\prime m k ′ , D k ′ C k \mathbb C_k C k
设顶点 i i i C k \mathbb C_k C k d i ( k ) d_i^{(k)} d i ( k ) i i i k k k m k ′ = m k + 1 2 d i ( k ) m_k^\prime=m_k+\frac 12 d_i^{(k)} m k ′ = m k + 2 1 d i ( k )
由于顶点 i i i C k \mathbb C_k C k D k ′ = D k + d i D_k^\prime=D_k+d_i D k ′ = D k + d i
因此有:
Δ Q = d i ( k ) 2 M − 2 D k × d i ( 2 M ) 2 \Delta Q=\frac{ d_i^{(k)}}{2M}-\frac{2D_k\times d_i}{(2M)^2} Δ Q = 2 M d i ( k ) − ( 2 M ) 2 2 D k × d i
如果 Δ Q > 0 \Delta Q \gt 0 Δ Q > 0 i i i C k \mathbb C_k C k 如果 Δ Q ≤ 0 \Delta Q \le 0 Δ Q ≤ 0 i i i 第二阶段称作 modularity Aggregation:将第一阶段划分出来的社区聚合成一个点,这相当于重新构造网络。
重复上述过程,直到网络中的结构不再改变为止。
Fast Unfolding 算法:
输入:
数据集 D = { x ⃗ 1 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\cdots,\mathbf{\vec x}_N\} D = { x 1 , ⋯ , x N } 输出:社区划分 C = { C 1 , ⋯ , C K } \mathcal C=\{\mathbb C_1,\cdots,\mathbb C_K\} C = { C 1 , ⋯ , C K }
算法步骤:
构建图:根据 D \mathbb D D G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E )
初始化社区:构建 N N N
此时每个社区有且仅有一个顶点。
迭代,迭代停止条件为:图保持不变 。迭代步骤为:
遍历每个顶点:
随机选择与其相连的顶点的社区,考察 Δ Q \Delta Q Δ Q Δ Q > 0 \Delta Q \gt 0 Δ Q > 0
重复上述过程,直到不能再增大modularity 为止。
构造新的图:将旧图中每个社区合并为新图中的每个顶点,旧社区之间的边的总权重合并为新图中的边的权重。
然后重复执行上述两步。
对于顶点 i i i Δ Q \Delta Q Δ Q Δ Q \Delta Q Δ Q
上述算法是串行执行:逐个选择顶点,重新计算其社区。在这个过程中其它顶点是不能变化的。
事实上可以将其改造为并行算法,在每一步迭代中同时更新多个顶点的信息。
Fast Unfolding 算法的结果比较理想,对比LPA 算法会更稳定。另外Fast Unfolding 算法不断合并顶点并构造新图,这会大大减少计算量。
LPA Usha 等人于 2007 年首次将标签传播算法用于社区发现。
不同于半监督学习,在社区发现中并没有任何样本的标注信息,这使得算法不稳定,可能得到多个不同的社区划分结果。
标签传播算法在迭代过程中,对于顶点 i i i i i i i i i i i i
如果多个社区出现的次数都是最多的,则随机选择一个。
标签传播算法:
输入:
数据集 D = { x ⃗ 1 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\cdots,\mathbf{\vec x}_N\} D = { x 1 , ⋯ , x N } 输出:社区划分 C = { C 1 , ⋯ , C K } \mathcal C=\{\mathbb C_1,\cdots,\mathbb C_K\} C = { C 1 , ⋯ , C K }
算法步骤:
标签传播算法的优点是:简单、高效、快速。缺点是每次迭代结果不稳定,准确率不高。
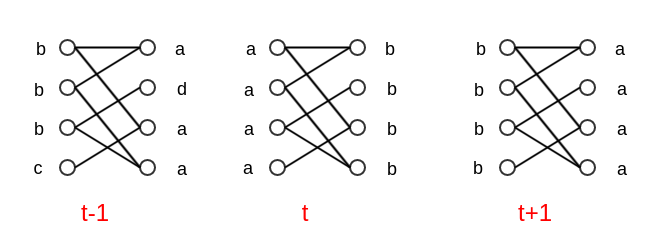
标签传播算法中,顶点的标签有同步更新和异步更新两种方式。
同步更新(假设更新次数为 t t t
c ( i ) = arg max k ∑ j ∈ N ( i ) I ( c ( j ) = k ) c(i) ^{}= \arg\max_{k} \sum_{j\in \mathbb N(i)} I(c(j)^{}=k) c ( i ) = arg k max j ∈ N ( i ) ∑ I ( c ( j ) = k )
同步更新方法在二分图中可能出现震荡的情况,如下图所示。
异步更新:
c ( i ) = arg max k ∑ j ∈ N ( i ) I ( c ( j ) = k ) c(i) ^{}= \arg\max_{k} \sum_{j\in \mathbb N(i)} I(c(j)^{}=k) c ( i ) = arg k max j ∈ N ( i ) ∑ I ( c ( j ) = k )
c ( j ) < n e w s t > c(j)^{<newst>} c ( j ) < n e w s t > j j j t − 1 t-1 t − 1 c ( j ) < n e w s t > = c ( j ) < t − 1 > c(j)^{<newst>}=c(j)^{<t-1>} c ( j ) < n e w s t > = c ( j ) < t − 1 > t t t c ( j ) < n e w s t > = c ( j ) < t > c(j)^{<newst>}=c(j)^{<t>} c ( j ) < n e w s t > = c ( j ) < t >
异步更新可以保证收敛,因此标签传播算法采用异步的策略更新顶点的标签,并在每次迭代之前对顶点重新进行随机排序从而保证顶点是随机遍历的。
标签传播算法的时间复杂度为 O ( N ) O(N) O ( N ) O ( N 2 ) O(N^2) O ( N 2 )
它既不需优化预定义的目标函数,也不需要关于社区的数量和规模等先验信息。
SLPA SLPA 由Jierui Xie 等人于 2011 年提出,它是一种重叠型社区发现算法。通过设定参数,也可以退化为非重叠型社区发现算法。
SLPA 与LPA 的重要区别:
SLPA 引入 Listener 和 Speaker 的概念。其中Listener 就是待更新标签的顶点, Speaker 就是该顶点的邻居顶点集合。
在LPA 中,Listener 的标签由 Speaker 中出现最多的标签决定。而SLPA 中引入了更多的规则。
SLPA 会记录每个顶点的历史标签序列。假设更新了 T T T T T T
当迭代停止之后,对每个顶点的历史标签序列中各标签出现的频率作出统计,按照某一给定的阈值 r r r
SLPA 算法:
输入:
数据集 D = { x ⃗ 1 , ⋯ , x ⃗ N } \mathbb D=\{\mathbf{\vec x}_1,\cdots,\mathbf{\vec x}_N\} D = { x 1 , ⋯ , x N } 迭代步数 T T T 标签频率阈值 r r r Speaker ruleListener rule输出:社区划分 C = { C 1 , ⋯ , C K } \mathcal C=\{\mathbb C_1,\cdots,\mathbb C_K\} C = { C 1 , ⋯ , C K }
算法步骤:
构建图:根据 D \mathbb D D G = ( V , E ) \mathcal G=(\mathbb V,\mathbb E) G = ( V , E )
初始化:为每个顶点分配一个标签队列;为每个顶点指定一个唯一的标签,并将标签加入到该顶点的标签队列中。
迭代 T T T
遍历每个顶点 i i i i i i r r r i i i
参考 https://zhuanlan.zhihu.com/p/134089340
https://github.com/Vay-keen/Machine-learning-learning-notes
https://github.com/familyld/Machine_Learning
https://zhuanlan.zhihu.com/p/25994179
https://leovan.me/cn/2018/12/ensemble-learning/
https://easyai.tech/ai-definition/ensemble-learning/
https://zhuanlan.zhihu.com/p/72415675
https://www.zhihu.com/question/63492375
https://www.zhihu.com/question/27068705
https://www.zhihu.com/question/19725590/answer/241988854
https://tangshusen.me/2018/10/27/SVM/
https://www.joinquant.com/view/community/detail/a98b7021e7391c62f6369207242700b2
https://zhuanlan.zhihu.com/p/79531731
https://github.com/Charmve/PaperWeeklyAI/blob/master/03_Maiwei AI PaperWeekly/03_机器学习%26深度学习理论/机器学习算法之——K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解.md
https://blog.csdn.net/zc02051126/article/details/49618633
https://zhuanlan.zhihu.com/p/127022333
https://0809zheng.github.io/2020/03/30/ridge.html
https://www.cnblogs.com/wuliytTaotao/p/10837533.html
https://link.springer.com/referenceworkentry/10.1007/978-1-4899-7687-1_910#Sec13186
http://palm.seu.edu.cn/zhangml/files/mla11-mll.pdf
https://blog.csdn.net/zwqjoy/article/details/80431496
https://ryuchen.club/posts/0x000034/ (推荐)
https://zhuanlan.zhihu.com/p/78798251
https://zhuanlan.zhihu.com/p/622244758
https://www.biaodianfu.com/hierarchical-clustering.html
https://zhuanlan.zhihu.com/p/411533418
https://zhuanlan.zhihu.com/p/33196506
https://www.cnblogs.com/wry789/p/13125658.html
https://blog.csdn.net/qq_41485273/article/details/113178117
https://www.jianshu.com/p/7d4323c28716
http://lunarnai.cn/2019/01/02/watermelon-chap-13/
【周志华机器学习】十三、半监督学习
https://zhuanlan.zhihu.com/p/411533418
https://www.huaxiaozhuan.com/统计学习/chapters/12_semi_supervised.html
https://blog.csdn.net/tyh70537/article/details/80244490
https://zhuanlan.zhihu.com/p/37747650
7125messi.github.io
https://blog.csdn.net/qq_40722827/article/details/104515955
https://www.cnblogs.com/dyl222/p/11055756.html
https://www.zhihu.com/tardis/zm/art/392908965
https://blog.csdn.net/j123kaishichufa/article/details/7679682
https://www.cnblogs.com/heaad/archive/2011/01/02/1924088.html
https://www.cnblogs.com/stevenlk/p/6543628.html
baidinghub.github.io-PCA
baidinghub.github.io-LDA
等等