
读paper16-微调LLM的APR与正确性验证
读paper16-微调LLM的APR与正确性验证
REEF: A Framework for Collecting Real-World Vulnerabilities and Fixes(数据集构建)
该Paper针对的是CVE,所以更准却的说应该是漏洞数据集构建框架,不过可以尝试借鉴思路进行缺陷数据集构建框架的搭建
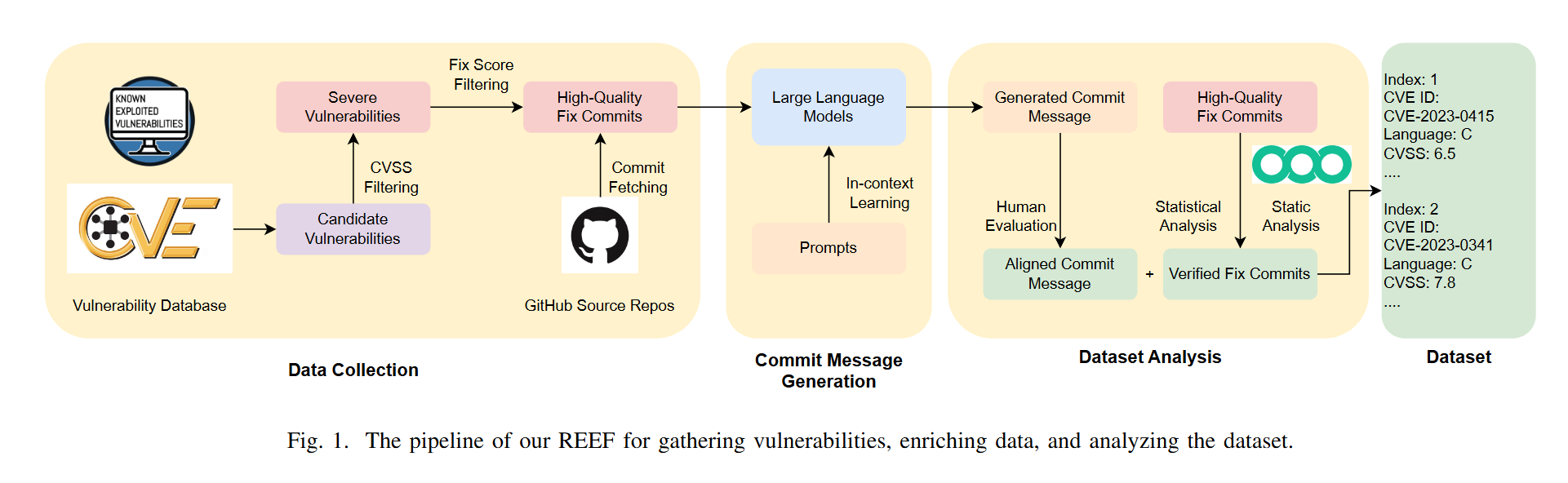
这种方法的好处是覆盖了较多的CWE规则,同时使用LLM对数据项进行了信息补全和完善。
但缺点是每条数据都会包含多个文件的修复,也就是说这种数据集更偏向项目级的修复。
工具和数据集在Github中给出:https://github.com/ASE-REEF 。C和cpp的数据量挺多的,但需要清洗。
RepairCAT: Applying Large Language Model to Fix Bugs in AI-Generated Programs
从数据集构造到模型微调的实现。使用LLM生成数据集进行模型微调。
数据集不进行缺陷定位,而是将整个有问题的程序一并处理,让模型决定修复的位置。
训练LLM和构建工具的源代码在Zenodo链接中存档:https://zenodo.org/records/8429188
工具与训练好的模型保存在docker:docker pull jiang719/repaircat-autocode-python,内容与上面链接中文件一样
不过会提示THIS IMAGE IS DEPRECATED and is scheduled for DELETION
此外:https://github.com/nus-apr/cerberus 。一个研究加速框架,它提供了多种先进程序分析工具(如 Infer 和 Pulse)、模糊测试工具(如 AFL++、Jazzer)以及程序修复工具(如 F1X、SelfAPR 等)的接口
APPT: Boosting Automated Patch Correctness Prediction via Fine-Tuning Pre-Trained Models
https://ieeexplore.ieee.org/document/10402095
https://github.com/iSEngLab/APPT
思路就是将修复前后代码嵌入到向量空间后用一个神经网络来判断代码修复是否正确。
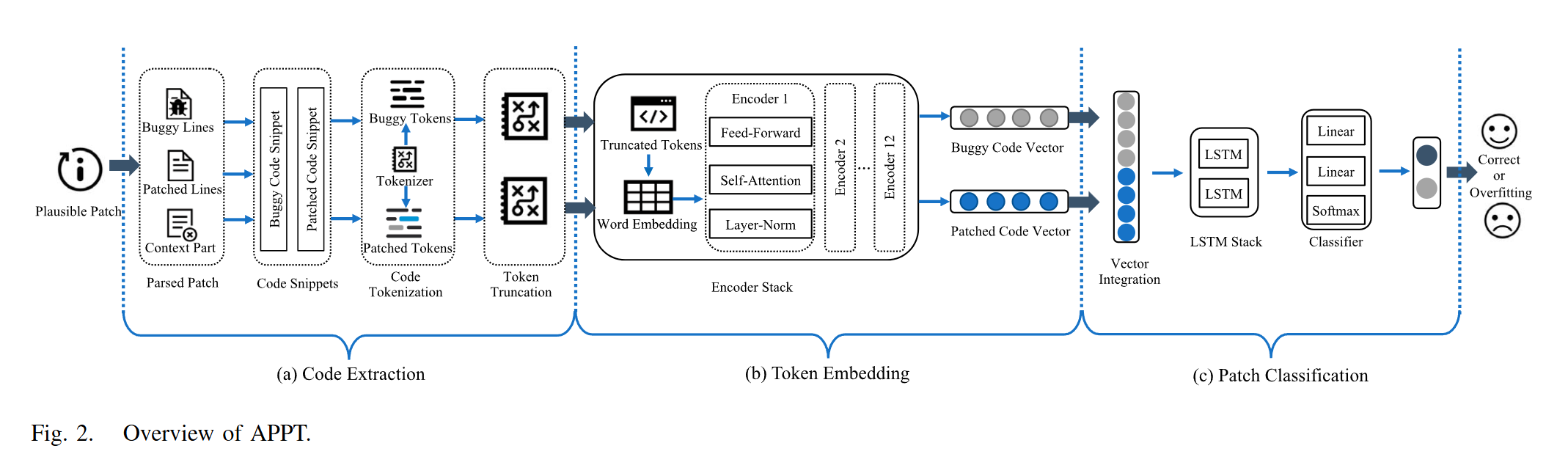
代码提取
一般来说APR会得到一个plausible patch,其中增删代码用“+、-”进行了标注,类似于Github的diff,因此可以从这个patch中得到缺陷代码段和修复后的代码段。
Tokenizer主要解决词汇量不足的问题,研究中保留了原有的标记化词汇,而不是使用字节对编码算法建立新的词汇,这样 APPT 就能继承自然语言理解能力,并从一个良好的起点开始学习预测。
此外由于预训练模型的输入长度受限(比如 BERT 的token输入长度限制为512),所以还需要截断。
嵌入
将代码的Tokens映射到向量空间。这每一层不就是transformer的编码器部分?代码实现是用BERT实现的。但是如果选择BERT的话必须进行微调,或者自己使用纯代码数据集从头进行训练。这部分在EXPERIMENT的Model Selection部分有提及。
分类
一个LSTM神经网络,将拼接后的向量进行二分类。
最后一个注意的点是向量拼接方式,使用torch.cat()优于其他方法
一些思考
论文的核心就是最后这个神经网络,但很关键的一点就是对这个网络的训练,修复的方法不止一种,需要加大数据量来避免这个神经网络的误判(但是现有数据集量本就不是很大),我觉得不如考虑智能体的方案。
CODEJUDGE : Evaluating Code Generation with Large Language Models:使用 slow thinking 的LLM进行代码评估
https://github.com/VichyTong/CodeJudge
主要分为两步,首先是对代码修复任务进行分析总结,然后将修复代码与修复任务进行对齐。
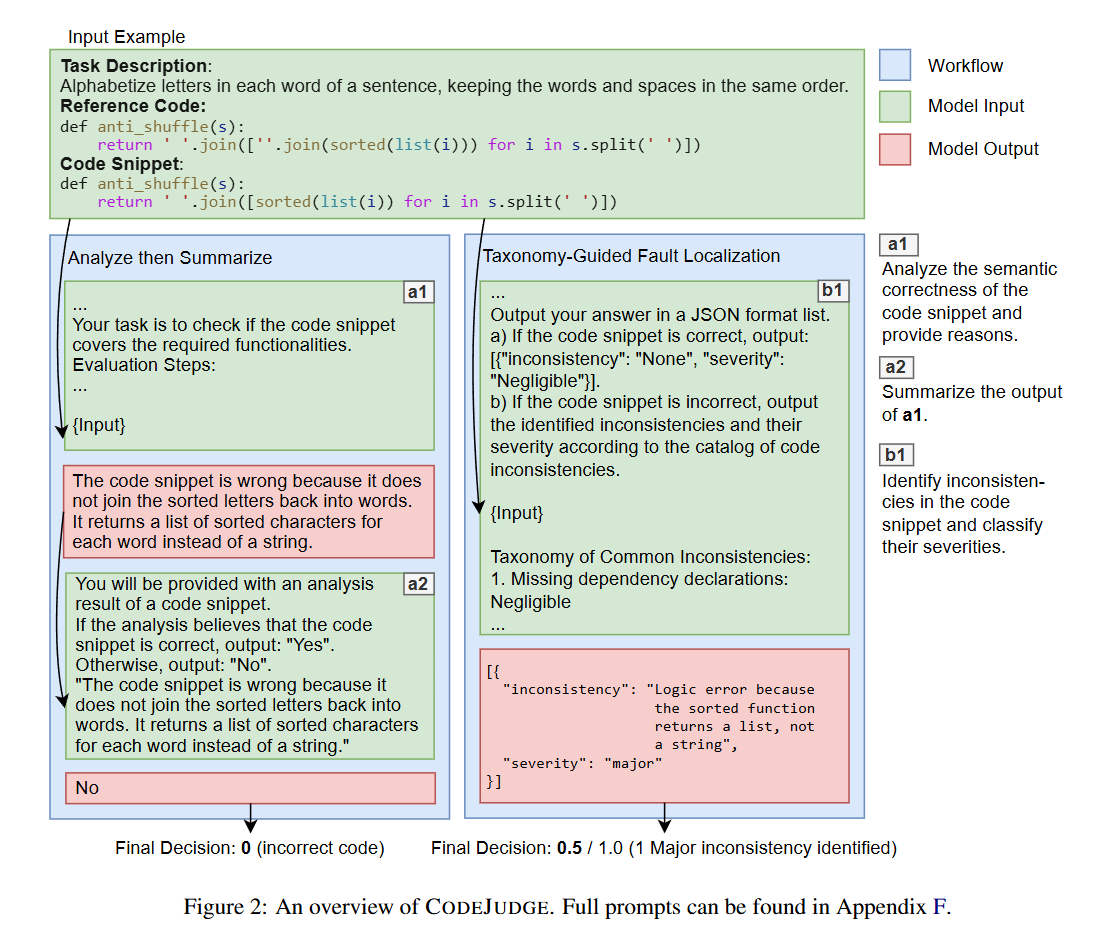
Analyze then Summarize:分析任务提供了一个逐步评估指南,要求 LLM 从任务描述中识别出所需功能,检查生成代码的逻辑,并报告任何未满足的要求。随后,要求 LLM 检查分析报告,并决定代码是否正确。
Taxonomy-Guided Fault Localization:将修复代码与修复任务的不一致程度划分为了四类共八种 level,最终计算得分来评判代码修复质量。

结果上来看效果不错: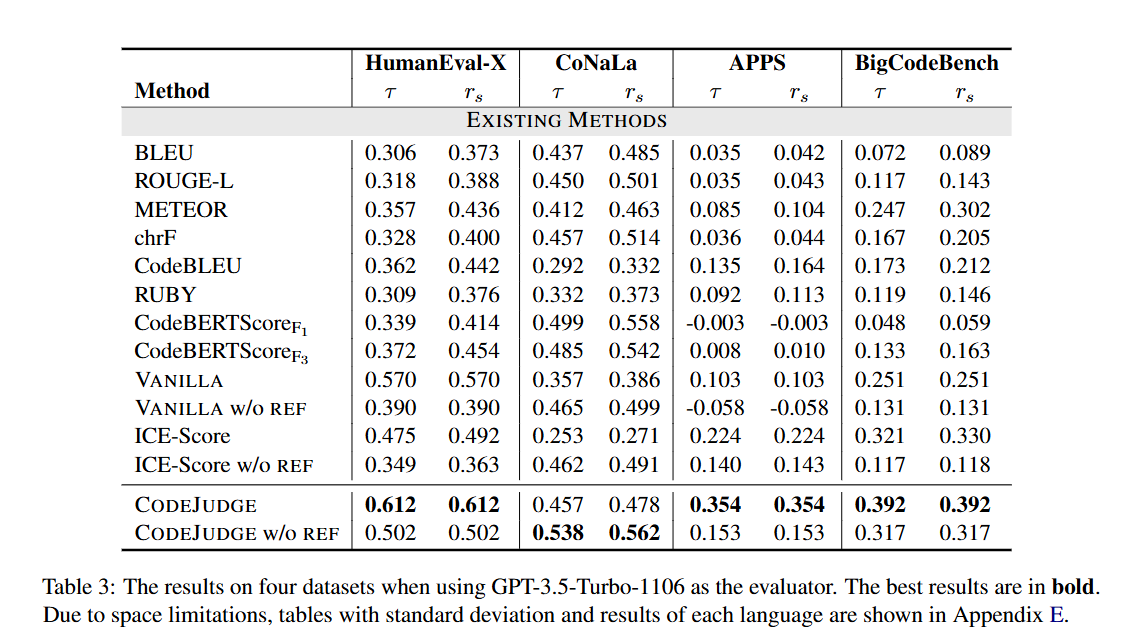
同时该研究对失败案例进行了分析:
- 代码逻辑分析错误(52.83%)。最常见的模式是 LLM 未能正确推断代码逻辑。例如,LLM 可能会提到代码实现了某种逻辑,但实际上并没有。(幻觉)
- 错误识别任务要求(26.42%)。对于一些复杂的任务,LLM 很难正确识别任务描述中的所有要求。
- 错误处理要求(20.75%)。我们发现 LLM 倾向于在生成的代码中报告许多错误处理错误(如不处理无效输入),尽管在许多情况下这并非必要。这使得 CODEJUDGE 在评估某些部分正确的代码时过于保守。








