关系数据库设计 背景 RDB设计工程方法的代表:E-R图方法
绘制 E-R E − R → R D B E-R\rightarrow RDB E − R → R D B 模式优化 RDB设计工程方法的问题
E-R质量和设计人员能力水平相关 E-R质量难以保证,致使E-R方法设计质量难以保证 其它RDB模式工程设计方法存在类似问题 模式规范化方法的研究状况
提出了模式规范化的标准:为决定因素1NF,2NF,3NF,BCNF,4NF,5NF,6NF 给出了泛关系分解到具体范式的算法 算法多为Np算法,无法实际执行 规范化方法学习价值
理解不同范式的优缺点 理解相应的模式改进方法 作为重要指导思想指导模式设计 本章讲述关系模式规范化理论、方法
好的关系设计特点
不必存储不必要的重复信息,同时又可以方便地获取信息 同数据本质结构相吻合 第一范式 如果某个域的元素被认为是不可再分的单元,那么这个域就是原子的(atomic)。如果一个关系模式R的所有的属性域都是原子的,我们称关系模式R属于第一范式(first normal form, 1NF)
关系数据库中的所有关系模式均应该满足1NF
原子域 域元素被认为是不可分的单元,称域是原子的
域原子性分析示例:
函数依赖 U U U α , β \alpha,\beta α , β
设 R ( U ) R(U) R ( U ) U U U α , β ⊆ U \alpha,\beta \subseteq U α , β ⊆ U r r r R ( U ) R(U) R ( U )
对 ∀ t , s ∈ r \forall t, s \in r ∀ t , s ∈ r t [ α ] = s [ α ] t[\alpha] = s[\alpha] t [ α ] = s [ α ] t [ β ] = s [ β ] t[\beta] = s[\beta] t [ β ] = s [ β ]
那么称 “α \alpha α β \beta β β \beta β α \alpha α α → β \alpha \rightarrow \beta α → β
称 α \alpha α β \beta β
平凡函数依赖 如果 α → β \alpha \rightarrow \beta α → β β ⊄ α \beta \not\subset \alpha β ⊂ α β ⊆ α \beta \subseteq \alpha β ⊆ α trivial)的函数依赖
如 ( s n o , s n a m e ) → s n a m e (sno,sname)\rightarrow sname ( s n o , s nam e ) → s nam e
平凡的函数依赖永远成立
部分函数依赖 在关系模式 R ( U ) R(U) R ( U ) α → β \alpha\rightarrow\beta α → β 任意 α \alpha α α ′ \alpha ' α ′ ,都有 α ′ ↛ β \alpha'\not\rightarrow\beta α ′ → β β \beta β α \alpha α α \alpha α β \beta β α → f β \alpha \overset f \rightarrow \beta α → f β β \beta β α \alpha α α → p β \alpha \overset p \rightarrow \beta α → p β α \alpha α β \beta β
例如:
( s n o , c n o ) → f s c o r e (sno,cno)\overset f \rightarrow score ( s n o , c n o ) → f score
( s n o , c n o ) → p s n a m e (sno,cno)\overset p \rightarrow sname ( s n o , c n o ) → p s nam e
传递函数依赖 在关系模式 R ( U ) R(U) R ( U ) α → β , β → γ , β ↛ α , β ⊄ α \alpha\rightarrow\beta,\,\beta\rightarrow\gamma,\,\beta\not\rightarrow\alpha,\,\beta\not\subset\alpha α → β , β → γ , β → α , β ⊂ α γ \gamma γ α \alpha α
函数依赖与码 设 K K K R < U , F > R< U, F > R < U , F > K → U K\rightarrow U K → U K K K R R R 设 K K K R < U , F > R< U, F > R < U , F > K → f U K\overset f \rightarrow U K → f U K K K R R R 包含在任意一个候选码 中的属性,称作主属性 函数依赖的推理规则 逻辑蕴涵 定义 关系模式 R R R F F F F F F α → β \alpha\rightarrow\beta α → β F F F α → β \alpha\rightarrow\beta α → β F ├ α → β F├ \,\,\alpha\rightarrow\beta F ├ α → β
另一种描述:给定关系模式 R R R F F F r r r f f f R R R f f f R R R F F F F ├ f F├ \,f F ├ f
被 F F F F F F (closure),记作:
F + = { α → β ∣ F ├ α → β } F^+=\{\alpha\rightarrow\beta\,|\,F├ \,\,\alpha\rightarrow\beta\,\} F + = { α → β ∣ F ├ α → β } R ( U , F ) R(U, F) R ( U , F ) U = X , Y U = {X, Y} U = X , Y F = X → Y F = {X\rightarrow Y} F = X → Y
Armstrong公理系统与正确性证明 所有希腊字母都是属性集,所有英文字母都是单个属性。
S 1 = { f ∣ 可用 A r m s t r o n g 公理从 F 中导出的函数依赖 f } S1 = \{ f \,|\,可用Armstrong公理从F中导出的函数依赖f \} S 1 = { f ∣ 可用 A r m s t ro n g 公理从 F 中导出的函数依赖 f }
S 2 = { f ∣ 被 F 所逻辑蕴涵的所有函数依赖 f } S2 = \{ f \,|\,被F所逻辑蕴涵的所有函数依赖f \} S 2 = { f ∣ 被 F 所逻辑蕴涵的所有函数依赖 f }
α , β , γ , δ \alpha,\beta,\gamma,\delta α , β , γ , δ
r r r R < U , F > R<U, F> R < U , F > t , s ∈ r t,s \in r t , s ∈ r t , s t,s t , s r r r
自反律(reflexivity) 若 β ⊆ α \beta\subseteq\alpha β ⊆ α α → β \alpha\rightarrow\beta α → β
不妨假设 t [ α ] = s [ α ] t[\alpha]=s[\alpha] t [ α ] = s [ α ] t [ β ] = s [ β ] t[\beta]=s[\beta] t [ β ] = s [ β ]
∵ t [ α ] = s [ α ] , β ⊆ α \because t[\alpha]=s[\alpha]\,,\,\beta\subseteq\alpha ∵ t [ α ] = s [ α ] , β ⊆ α
∴ t [ β ] = s [ β ] \therefore t[\beta]=s[\beta] ∴ t [ β ] = s [ β ]
∴ α → β \therefore \alpha\rightarrow\beta ∴ α → β
增广律(augmentation) 若 α → β \alpha\rightarrow\beta α → β α γ → β γ \alpha\gamma\rightarrow\beta\gamma α γ → β γ
∵ 不妨假设 t [ α γ ] = s [ α γ ] \because 不妨假设\, t[\alpha\gamma] = s[\alpha\gamma] ∵ 不妨假设 t [ α γ ] = s [ α γ ]
∴ t [ α ] = s [ α ] , t [ γ ] = s [ γ ] \therefore t[\alpha]=s[\alpha],t[\gamma]=s[\gamma] ∴ t [ α ] = s [ α ] , t [ γ ] = s [ γ ]
∵ α → β \because \alpha\rightarrow\beta ∵ α → β
∴ t [ β ] = s [ β ] \therefore t[\beta] = s[\beta] ∴ t [ β ] = s [ β ]
∴ t [ β γ ] = s [ β γ ] \therefore t[\beta\gamma]=s[\beta\gamma] ∴ t [ β γ ] = s [ β γ ]
∴ α γ → β γ \therefore \alpha\gamma\rightarrow\beta\gamma ∴ α γ → β γ
传递律(transitivity) 若 α → β , β → γ \alpha\rightarrow\beta,\,\beta\rightarrow\gamma α → β , β → γ α → γ \alpha\rightarrow\gamma α → γ
∵ α → β , 假设 t [ α ] = s [ α ] \because \alpha\rightarrow\beta,假设\,t[\alpha]=s[\alpha] ∵ α → β , 假设 t [ α ] = s [ α ]
∴ t [ β ] = s [ β ] \therefore t[\beta]=s[\beta] ∴ t [ β ] = s [ β ]
∵ β → γ \because\beta\rightarrow\gamma ∵ β → γ
∴ t [ γ ] = s [ γ ] \therefore t[\gamma] = s[\gamma] ∴ t [ γ ] = s [ γ ]
∴ α → β \therefore \alpha\rightarrow\beta ∴ α → β
合并律(union rule) 若 α → β \alpha \rightarrow \beta α → β α → γ \alpha\rightarrow\gamma α → γ α → β γ \alpha\rightarrow\beta\gamma α → β γ
∵ 假设 t [ α ] = s [ α ] \because 假设\,t[\alpha]=s[\alpha] ∵ 假设 t [ α ] = s [ α ]
∴ t [ β ] = s [ β ] , t [ γ ] = s [ γ ] \therefore t[\beta]=s[\beta],\,t[\gamma]=s[\gamma] ∴ t [ β ] = s [ β ] , t [ γ ] = s [ γ ]
∴ t [ β γ ] = s [ β γ ] \therefore t[\beta\gamma]=s[\beta\gamma] ∴ t [ β γ ] = s [ β γ ]
∴ α → β γ \therefore \alpha\rightarrow\beta\gamma ∴ α → β γ
或者使用增广律和传递律:
∵ α → β , α → γ \because \alpha \rightarrow \beta, \alpha\rightarrow\gamma ∵ α → β , α → γ
∴ α → α β , α β → β γ \therefore \alpha\rightarrow\alpha\beta,\alpha\beta\rightarrow\beta\gamma ∴ α → α β , α β → β γ
∴ α → β γ \therefore\alpha\rightarrow\beta\gamma ∴ α → β γ
分解律(decomposition rule) 若 α → β γ \alpha\rightarrow\beta\gamma α → β γ α → β \alpha\rightarrow\beta α → β α → γ \alpha\rightarrow\gamma α → γ
∵ γ ⊆ β γ \because\gamma\subseteq\beta\gamma ∵ γ ⊆ β γ
∴ β γ → γ \therefore \beta\gamma\rightarrow\gamma ∴ β γ → γ
∵ α → β γ \because \alpha\rightarrow\beta\gamma ∵ α → β γ
∴ α → γ \therefore \alpha\rightarrow\gamma ∴ α → γ
同理 α → β 同理\,\alpha\rightarrow\beta 同理 α → β
伪传递律(pseudotransitivity rule) 若 α → β \alpha \rightarrow \beta α → β γ β → δ \gamma\beta \rightarrow \delta γ β → δ γ α → δ \gamma\alpha \rightarrow \delta γ α → δ
∵ α → β \because \alpha\rightarrow\beta ∵ α → β
∴ α γ → γ β \therefore \alpha\gamma\rightarrow\gamma\beta ∴ α γ → γ β
∵ γ β → δ \because \gamma\beta\rightarrow\delta ∵ γ β → δ
∴ γ α → δ \therefore \gamma\alpha\rightarrow\delta ∴ γ α → δ
Armstrong公理与闭包问题 一般来说,F ⊂ F + F\subset F^+ F ⊂ F + F F F F + F^+ F +
但这其实是一个NP问题,也就是说,对于 α → β ∈ F + \alpha\rightarrow\beta\in F^+ α → β ∈ F + α \alpha α β \beta β α , β \alpha,\beta α , β 2 n 2^n 2 n 2 n × 2 n = 2 2 n 2^n\times2^n=2^{2n} 2 n × 2 n = 2 2 n
属性集的闭包(Attribute Closure) 令 α \alpha α 函数依赖集 F F F 被 α \alpha α 属性的集合 称作 F F F α \alpha α α F + \alpha^+_F α F +
a F + = { A ∣ a → A 能由 F 出发根据 A r m s t r o n g 公理导出 } a^+_F= \{ A \,|\, a \rightarrow A能由F出发根据Armstrong公理导出 \} a F + = { A ∣ a → A 能由 F 出发根据 A r m s t ro n g 公理导出 }
示例 :
R < U , F > R< U, F > R < U , F > U = { A , B , C } U=\{A,B,C\} U = { A , B , C }
函数依赖集 F = { A → B , B → C } F=\{A \rightarrow B,B \rightarrow C\} F = { A → B , B → C }
则
A F + = { A , B , C } A^+_F = \{A,B,C\} A F + = { A , B , C }
B F + = { B , C } B^+_F = \{B,C\} B F + = { B , C }
C F + = { C } C^+_F = \{C\} C F + = { C }
函数依赖集的闭包转化为属性集的闭包 判定 α → β \alpha\rightarrow \beta α → β F F F α F + \alpha^+_F α F + β ⊆ α F + \beta \subseteq \alpha^+_F β ⊆ α F +
算法(计算基于函数依赖集 F F F α \alpha α 属性集闭包算法的完备性(算法能够找出 a F + a^+_F a F +
在算法执行过程中,如果存在某个属性应该属于 a F + a^+_F a F + β → γ ( b ⊆ r e s u l t ) \beta \rightarrow \gamma(b \subseteq result) β → γ ( b ⊆ res u lt ) γ \gamma γ
当算法结束时,所有函数依赖均已被处理过,γ \gamma γ a F + a^+_F a F +
示例 R < U , F > , U = ( A , B , C , G , H , I ) , F = { A → B , A → C , C G → H , C G → I , B → H } R< U, F >, U = (A, B, C, G, H, I), F = \{A\rightarrow B, A\rightarrow C, CG\rightarrow H, CG\rightarrow I, B\rightarrow H\} R < U , F > , U = ( A , B , C , G , H , I ) , F = { A → B , A → C , CG → H , CG → I , B → H } ( A G ) F + (AG)^+_F ( A G ) F +
R < U , F > , U = ( C , T , H , R , S ) , F = { C → T , H R → C , H T → R , H S → R } R< U, F >, U = (C, T, H, R, S),F = \{C\rightarrow T, HR\rightarrow C, HT\rightarrow R, HS\rightarrow R\} R < U , F > , U = ( C , T , H , R , S ) , F = { C → T , H R → C , H T → R , H S → R }
问题:HR是候选码吗?HS呢?
( H R ) F + = { H R C T } (HR)^+_F=\{HRCT\} ( H R ) F + = { H RCT }
( H S ) F + = { H S R C T } (HS)^+_F=\{HSRCT\} ( H S ) F + = { H SRCT } H F + = { H } , S F + = { S } H^+_F=\{H\},S^+_F=\{S\} H F + = { H } , S F + = { S }
Armstrong公理完备性证明 Armstrong公理完备性的含义:F + F^+ F + F F F
要证明完备性,首先计算 F + F^+ F + F + F^+ F +
Armstrong公理完备性证明:证明完备性的的逆否命题 :即如果函数依赖性 α → β \alpha\rightarrow\beta α → β F F F α → β \alpha\rightarrow\beta α → β F F F 。证明分三步。
证明如下:
若 V → W V\rightarrow W V → W V ⊆ α F + V\subseteq \alpha_F^+ V ⊆ α F + W ⊆ α F + W\subseteq \alpha_F^+ W ⊆ α F +
证明:因为:α → α + , V ⊆ α F + \alpha \rightarrow \alpha^+,V\subseteq \alpha_F^+ α → α + , V ⊆ α F + α → V \alpha \rightarrow V α → V V → W V\rightarrow W V → W α → W \alpha \rightarrow W α → W W ⊆ α F + W\subseteq \alpha_F^+ W ⊆ α F + 构造一张二维表 r r r r r r R < U , F > R<U,F> R < U , F > ,即 F F F r r r
a F + a_F^+ a F + U − a F + U - a_F^+ U − a F +
11……….1 00……….0
11……….1 11……….1
假设 r r r R < U , F > R<U,F> R < U , F > V → W ∈ F V\rightarrow W\in F V → W ∈ F V → W V\rightarrow W V → W r r r r r r V → W V\rightarrow W V → W r r r V ⊆ F + V\subseteq F^+ V ⊆ F + W W W a F + a_F^+ a F + W ⊈ F + W\not\subseteq F^+ W ⊆ F + R < U , F > R<U,F> R < U , F >
若 α → β \alpha\rightarrow\beta α → β F F F β \beta β a F + a_F^+ a F + β \beta β β ’ \beta’ β ’ β ⊆ U − a F + \beta \subseteq U - a_F^+ β ⊆ U − a F + α → β \alpha\rightarrow\beta α → β r r r α → β \alpha\rightarrow\beta α → β F F F 补充:候选码的求解理论和算法 属性集的闭包包含了所有属性,则说明这是超码,只有当其所有可能的真子集都不是超码,这才是候选码。这是一个NP问题。
如何判断一个属性集是否候选码。
下面我们给出简易的方法:
对于给定的关系模式 R ( U , F ) R(U,F) R ( U , F )
L类:仅出现在F的函数依赖左部 的属性
R类:仅出现在F的函数依赖右部 的属性
N类:在F的函数依赖两边均未出现 的属性
LR类:在F的函数依赖两边均出现 的属性
定理1:对于给定的关系模式 R ( U , F ) R(U,F) R ( U , F ) α ( α ⊆ U ) \alpha (\alpha \subseteq U) α ( α ⊆ U ) L类属性,则 α \alpha α R R R
例:设关系模式 R ( U , F ) , U = { A , B , C , D } , F = { D → B , B → D , A D → B , A C → D } R(U,F),U = \{A,B,C,D\},F = \{D \rightarrow B,B \rightarrow D,AD \rightarrow B,AC \rightarrow D\} R ( U , F ) , U = { A , B , C , D } , F = { D → B , B → D , A D → B , A C → D }
解:A A A C C C L类属性, A C AC A C R R R ( A C ) F + = { A C D B } (AC)_F^+ = \{ACDB\} ( A C ) F + = { A C D B } ( A ) F + = { A } (A)_F^+ = \{A\} ( A ) F + = { A } ( C ) F + = { C } (C)_F^+ = \{C\} ( C ) F + = { C } A C AC A C R R R
推论:对于给定的关系模式 R ( U , F ) R(U,F) R ( U , F ) α ( α ⊆ U ) \alpha (\alpha \subseteq U) α ( α ⊆ U ) α F + \alpha_F^+ α F + α \alpha α R ( U , F ) R(U,F) R ( U , F )
定理2:对于给定的关系模式 R ( U , F ) R(U,F) R ( U , F ) α ( α ⊆ U ) \alpha (\alpha \subseteq U) α ( α ⊆ U ) α \alpha α R ( U , F ) R(U,F) R ( U , F )
定理3:对于给定的关系模式 R ( U , F ) R(U,F) R ( U , F ) α ( α ⊆ U ) \alpha (\alpha \subseteq U) α ( α ⊆ U ) α \alpha α R ( U , F ) R(U,F) R ( U , F )
示例1:设有关系模式 R ( U , F ) , U = { A , B , C , D , E , P } , F = { A → D , E → D , D → B , B C → D , D C → A } R(U,F),U = \{A,B,C,D,E,P\},F = \{A \rightarrow D,E \rightarrow D,D \rightarrow B,BC \rightarrow D,DC \rightarrow A\} R ( U , F ) , U = { A , B , C , D , E , P } , F = { A → D , E → D , D → B , BC → D , D C → A } R R R
解:C E CE CE L 类属性,C E CE CE P P P N 类属性,P P P ( C E P ) F + = { A B C D E P } (CEP)_F^+ = \{ABCDEP\} ( CEP ) F + = { A BC D EP } C E P CEP CEP C E P CEP CEP
示例2:假设有关系模式 R ( U , F ) , U = { A , B , C , D , E } , F = { A → D , E → D , D → B , B C → D , D C → A } R(U,F),U = \{A,B,C,D,E\},F = \{A \rightarrow D,E \rightarrow D,D \rightarrow B,BC \rightarrow D,DC \rightarrow A\} R ( U , F ) , U = { A , B , C , D , E } , F = { A → D , E → D , D → B , BC → D , D C → A } R R R
解:C E CE CE C E CE CE ( C E ) F + = { A B C D E } (CE)_F^+ = \{ABCDE\} ( CE ) F + = { A BC D E } C E CE CE C E CE CE R R R
示例3:假设有关系模式R ( U , F ) , U = { A , B , C , D , E } , F = { A → B C , C D → E , B → D , E → A } R(U,F),U = \{A,B,C,D,E\},F = \{A \rightarrow BC,CD \rightarrow E,B \rightarrow D,E \rightarrow A\} R ( U , F ) , U = { A , B , C , D , E } , F = { A → BC , C D → E , B → D , E → A } R R R
解:A B C D E ABCDE A BC D E F F F LR),因此,候选码可能包含 A B C D E ABCDE A BC D E
可以除去 A B C D ABCD A BC D E E E ( E ) F + = { A B C D E } (E)_F^+ = \{ABCDE\} ( E ) F + = { A BC D E } E E E 因为 C D → E CD\rightarrow E C D → E ( C D ) F + = { A B C D E } (CD)_F^+ = \{ABCDE\} ( C D ) F + = { A BC D E } C F + = { C } , D F + = { D } C_F^+ = \{C\},D_F^+ = \{D\} C F + = { C } , D F + = { D } C D CD C D 可除去 A D E ADE A D E B C BC BC ( B C ) F + = { A B C D E } (BC)_F^+ = \{ABCDE\} ( BC ) F + = { A BC D E } B F + = { B D } B_F^+ = \{BD\} B F + = { B D } C F + = { C } C_F^+ = \{C\} C F + = { C } B C BC BC 还可除去 B C D E BCDE BC D E A A A 这道题的主要收获就是我们往往可以通过一个确定的候选码以及与这个候选码相关的函数依赖来推断其他的候选码。如做这道题时我先确定了 C D CD C D B → D B\rightarrow D B → D B C BC BC A → B C A\rightarrow BC A → BC A A A E → A E\rightarrow A E → A E E E 正则覆盖 假设在一个关系模式上有一个函数依赖集 F F F
可以通过测试与给定函数依赖集有相同闭包的简化集的方式,来降低检测的开销
函数依赖集的等价和覆盖 函数依赖集 F , G F,G F , G 若 F + = G + F^+= G^+ F + = G + F F F G G G 。
若 F F F G G G F F F G G G G G G F F F
F + = G + ⟺ F ⊆ G + , G ⊆ F + F^+ = G^+ \iff F \subseteq G^+,G \subseteq F^+ F + = G + ⟺ F ⊆ G + , G ⊆ F +
如果去除一个函数依赖中的属性,不会改变该函数依赖集的闭包,则称该属性是无关的(extraneous)
对于函数依赖集 F F F F F F α → β α\rightarrowβ α → β A A A α \alpha α A ∈ α A∈α A ∈ α F ├ ( F – { α → β } ) ∪ { ( α − A ) → β } F├ (F – \{\alpha\rightarrow\beta\})∪\{(\alpha- A) \rightarrow \beta\} F ├ ( F – { α → β }) ∪ {( α − A ) → β } F F F ( F – { α → β } ) ∪ { ( α − A ) → β } (F – \{α\rightarrowβ\})∪\{(α- A) \rightarrowβ\} ( F – { α → β }) ∪ {( α − A ) → β }
为什么不考虑( F – { α → β } ) ∪ { ( α − A ) → β } ├ F (F – \{α\rightarrowβ\})∪\{(α- A) \rightarrowβ\}├ F ( F – { α → β }) ∪ {( α − A ) → β } ├ F 我们假设右面的函数依赖集为 G G G F F F F { − , − , α → β , − , − } F\{-,-,\alpha \rightarrow\beta,-,-\} F { − , − , α → β , − , − } G { − , − , ( α − A ) → β , − , − } G\{-,-,(\alpha-A)\rightarrow\beta,-,-\} G { − , − , ( α − A ) → β , − , − } ( α − A ) → β (\alpha-A)\rightarrow\beta ( α − A ) → β α → β \alpha\rightarrow\beta α → β 对于函数依赖集 F F F F F F α → β α\rightarrowβ α → β A A A β \beta β A ∈ β A∈\beta A ∈ β ( F – { α → β } ) ∪ { α → ( β − A ) } ├ F (F – \{α\rightarrowβ\})∪\{α \rightarrow (β-A)\}├\,F ( F – { α → β }) ∪ { α → ( β − A )} ├ F ( F – { α → β } ) ∪ { α → ( β − A ) } (F – \{α\rightarrowβ\})∪\{α \rightarrow (β-A)\} ( F – { α → β }) ∪ { α → ( β − A )} F F F
为什么不考虑 F ├ ( F – { α → β } ) ∪ { α → ( β − A ) } F├ (F – \{α\rightarrowβ\})∪\{α \rightarrow (β-A)\} F ├ ( F – { α → β }) ∪ { α → ( β − A )} 同上,α → β \alpha\rightarrow\beta α → β A ∈ β A\in \beta A ∈ β α → ( β − A ) \alpha\rightarrow (\beta-A) α → ( β − A ) 无关属性的核心:能够被函数依赖集 F F F
示例 F 1 = { A B → C , A → C } F_1 = \{AB \rightarrow C,A \rightarrow C\} F 1 = { A B → C , A → C }
F 2 = { A B → C D , A → C } F_2 = \{AB \rightarrow CD, A \rightarrow C\} F 2 = { A B → C D , A → C }
请找出上述两个函数依赖集中的无关属性
在 F 1 F_1 F 1 B B B A B → C AB \rightarrow C A B → C
在 F 2 F_2 F 2 C C C A B → C D AB \rightarrow CD A B → C D
检验无关属性的方法 考虑 α → β α\rightarrow β α → β A A A
如果 A ∈ α A\in α A ∈ α γ = α − { A } \gamma = α- \{A\} γ = α − { A } γ → β \gamma\rightarrow β γ → β F F F F F F γ F + \gamma_F^+ γ F + γ F + \gamma_F^+ γ F + β β β A A A α α α 如果 A ∈ β A\in β A ∈ β F ’ = ( F − { α → β } ) ∪ { α → ( β − A ) } F’= ( F - \{α\rightarrow β\})∪\{α\rightarrow (β - A) \} F ’ = ( F − { α → β }) ∪ { α → ( β − A )} α → A α\rightarrow A α → A F ’ F’ F ’ F ’ F’ F ’ α F ’ + α_{F’}^+ α F ’ + α F ’ + α_{F’}^+ α F ’ + β β β 注意处理无关属性的时候一次只处理一个函数依赖。 小技巧:若 α → β γ , β → γ \alpha\rightarrow\beta\gamma,\beta\rightarrow\gamma α → β γ , β → γ γ \gamma γ α → γ \alpha\rightarrow\gamma α → γ
若 α → β γ , α β → . . . \alpha\rightarrow\beta\gamma,\alpha\beta\rightarrow... α → β γ , α β → ... β \beta β
样例 F = { A B → C D , A → E , E → C } F=\{AB \rightarrow CD, A \rightarrow E, E \rightarrow C\} F = { A B → C D , A → E , E → C } C C C A B → C D AB \rightarrow CD A B → C D
F ’ = { A B → D , A → E , E → C } F’=\{AB \rightarrow D, A \rightarrow E, E \rightarrow C\} F ’ = { A B → D , A → E , E → C } A B AB A B { A B C D E } \{ABCDE\} { A BC D E } C C C A B → C D AB \rightarrow CD A B → C D
或者,显然 A → C A\rightarrow C A → C A B → C AB\rightarrow C A B → C C C C A B → C D AB \rightarrow CD A B → C D
正则覆盖(Canonical Cover) 满足下列条件的函数依赖集 F F F F c F_c F c
注意:正则覆盖未必唯一
计算算法 算法—计算函数依赖集 F F F F c F_c F c
F c = F F_c = F F c = F
REPEAT
使用合并律将 F c F_c F c α → β α\rightarrow β α → β α → γ α\rightarrow \gamma α → γ α → β γ α \rightarrow β\gamma α → β γ
找出在含无关属性的函数依赖 α → β α\rightarrow β α → β α → β α\rightarrow β α → β
UNTIL F c F_c F c
注意:
检查无关属性是基于当前函数依赖集合中的函数依赖,而不是原始的 F F F
也就是说,检查无关属性的属性集是基于上一次的属性集的处理结果 不能同时讨论一个函数依赖中的两个属性的无关性,一次只能讨论一个属性
如果一个函数依赖的右半部只包含一个属性,例如, A → C A \rightarrow C A → C 删除
从某种意义上说,F c F_c F c F c F_c F c F F F
最小覆盖 最小覆盖定义(补充):
关系模式 R ( U , F ) R(U,F) R ( U , F ) F F F F m F_m F m F m F_m F m F m ⟺ F Fm\iff F F m ⟺ F
F m F_m F m
F m F_m F m 右端属性是唯一的
示例: R ( U , F ) , U = { A , B , C } , F = { A → B C , B → A C , C → A B } R(U,F) , U = \{A,B,C\},F=\{A→BC,B→AC,C→AB\} R ( U , F ) , U = { A , B , C } , F = { A → BC , B → A C , C → A B }
F c / F m : A → B , B → C , C → A F_c/F_m:A\rightarrow B,B\rightarrow C,C\rightarrow A F c / F m : A → B , B → C , C → A
F c / F m : A → C , C → B , B → A F_c/F_m : A→C,C→B,B→A F c / F m : A → C , C → B , B → A
F c : A → B C , B → A , C → A F_c : A\rightarrow BC,B\rightarrow A,C\rightarrow A F c : A → BC , B → A , C → A
F m : A → B , A → C , B → A , C → A F_m : A\rightarrow B, A\rightarrow C,B\rightarrow A,C\rightarrow A F m : A → B , A → C , B → A , C → A
正则覆盖样例 F = { A → B C , B → C , A → B , A B → C } F = \{A \rightarrow BC,B\rightarrow C,A\rightarrow B,AB\rightarrow C\} F = { A → BC , B → C , A → B , A B → C } F c F_c F c
合并 A → B C A\rightarrow BC A → BC A → B A\rightarrow B A → B A → B C A\rightarrow BC A → BC
F 1 = { A → B C , B → C , A B → C } F_1 = \{A\rightarrow BC,B\rightarrow C,AB\rightarrow C\} F 1 = { A → BC , B → C , A B → C } B B B A B → C AB\rightarrow C A B → C
F 2 = { A → B C , B → C , A → C } F_2 = \{A\rightarrow BC,B\rightarrow C,A\rightarrow C\} F 2 = { A → BC , B → C , A → C } 合并 A → B C A\rightarrow BC A → BC A → C A\rightarrow C A → C A → B C A\rightarrow BC A → BC
F 3 = { A → B C , B → C } F_3 = \{A\rightarrow BC,B\rightarrow C\} F 3 = { A → BC , B → C } C C C A → B C A\rightarrow BC A → BC
F c = { A → B , B → C } F_c = \{A\rightarrow B,B\rightarrow C\} F c = { A → B , B → C } 示例2
F = { A B → C E , A → C , G P → B , E P → A , C D E → P , H B → P , D → H G , A B C → P G } F=\{AB \rightarrow CE,A \rightarrow C,GP \rightarrow B,EP \rightarrow A,CDE \rightarrow P,HB \rightarrow P,D \rightarrow HG,ABC \rightarrow PG\} F = { A B → CE , A → C , GP → B , EP → A , C D E → P , H B → P , D → H G , A BC → PG } F c F_c F c
没有可以合并的函数依赖
在 A B → C E AB \rightarrow CE A B → CE A → C A \rightarrow C A → C
F 1 = { A B → E , A → C , G P → B , E P → A , C D E → P , H B → P , D → H G , A B C → P G } F_1 = \{AB \rightarrow E,A \rightarrow C,GP \rightarrow B,EP \rightarrow A,CDE \rightarrow P,HB \rightarrow P,D \rightarrow HG,ABC \rightarrow PG\} F 1 = { A B → E , A → C , GP → B , EP → A , C D E → P , H B → P , D → H G , A BC → PG } 因为 A → C , A B C → P G A \rightarrow C, ABC \rightarrow PG A → C , A BC → PG
F c = { A B → E , A → C , G P → B , E P → A , C D E → P , H B → P , D → H G , A B → P G } F_c = \{AB \rightarrow E,A \rightarrow C,GP \rightarrow B,EP \rightarrow A,CDE \rightarrow P,HB \rightarrow P,D \rightarrow HG,AB \rightarrow PG\} F c = { A B → E , A → C , GP → B , EP → A , C D E → P , H B → P , D → H G , A B → PG }
示例3
模式 R ( U , F ) , U = { A , B , C } , F = { A → B C , B → A C , C → A B } R(U,F),U = \{A,B,C\},F=\{A→BC, B→AC, C→AB\} R ( U , F ) , U = { A , B , C } , F = { A → BC , B → A C , C → A B }
正则覆盖有多个:
F c 1 = { A → B , B → C , C → A } F_{c1}=\{A→B, B→C, C→A\} F c 1 = { A → B , B → C , C → A }
F = { A → B C , B → A C , C → A B } F=\{A→BC, B→AC, C→AB\} F = { A → BC , B → A C , C → A B }
F 1 = { A → B , B → A C , C → A B } F_1=\{A→B, B→AC, C→AB\} F 1 = { A → B , B → A C , C → A B }
F 2 = { A → B , B → C , C → A B } F_2=\{A→B, B→C, C→AB\} F 2 = { A → B , B → C , C → A B }
F c = { A → B , B → C , C → A } F_c=\{A→B, B→C, C→A\} F c = { A → B , B → C , C → A }
F c 2 = { A → B , B → A C , C → B } F_{c2}=\{A→B, B→AC, C→B\} F c 2 = { A → B , B → A C , C → B }
F c 3 = { A → C , C → B , B → A } F_{c3}=\{A→C, C→B , B→A\} F c 3 = { A → C , C → B , B → A }
F c 4 = { A → C , B → C , C → A B } F_{c4}=\{A→C, B→C, C→AB\} F c 4 = { A → C , B → C , C → A B }
F c 5 = { A → B C , B → A , C → A } F_{c5} = \{A→BC, B→A, C→A\} F c 5 = { A → BC , B → A , C → A }
示例4
F = { E → G , G → E , F → E G , H → E G , F H → E } F=\{E → G,G → E,F → EG,H → EG,FH → E\} F = { E → G , G → E , F → EG , H → EG , F H → E } F c F_c F c
1、无需合并
2、在 F H → E FH → E F H → E F F F F 1 = { E → G , G → E , F → E G , H → E G } F_1=\{E → G,G → E,F → EG,H → EG\} F 1 = { E → G , G → E , F → EG , H → EG }
3、在 F 1 F_1 F 1 F → E G F → EG F → EG H → E G H → EG H → EG E G EG EG
最终: F c 1 = { E → G , G → E , F → G , H → G } F_{c1}= \{E → G,G → E,F → G,H → G\} F c 1 = { E → G , G → E , F → G , H → G }
F c 2 = { E → G , G → E , F → G , H → E } F_{c2}= \{E → G,G → E,F → G,H → E\} F c 2 = { E → G , G → E , F → G , H → E }
F c 3 = { E → G , G → E , F → E , H → E } F_{c3}= \{E → G,G → E,F → E,H → E\} F c 3 = { E → G , G → E , F → E , H → E }
F c 4 = { E → G , G → E , F → E , H → G } F_{c4}= \{E → G,G → E,F → E,H → G\} F c 4 = { E → G , G → E , F → E , H → G }
示例5
关系模式 R , U = { A , B , C , D , E } R,U = \{A,B,C,D,E\} R , U = { A , B , C , D , E } F F F G G G F = { A → B , A B → C , D → A C , D → E } F = \{A → B,AB → C,D → AC,D → E\} F = { A → B , A B → C , D → A C , D → E } G = { A → B C , D → A E } G = \{A → BC,D → AE\} G = { A → BC , D → A E } F F F G G G
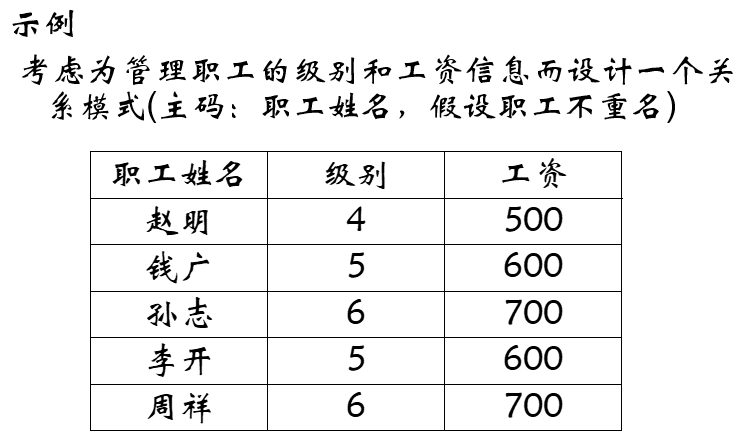
关系模式的设计问题 示例 考虑为管理职工的级别和工资信息而设计一个关系模式(主码:职工姓名,假设职工不重名)
信息的不可表示问题
插入异常 :如果没有职工具有8级工资,则8级工资的工资数额就难以插入删除异常 :如果仅有职工赵明具有4级工资,如果将赵明删除,则有关4级工资的工资数额信息也随之删除了信息的冗余问题
数据冗余 :职工很多,工资级别有限,每一级别的工资数额反复存储多次更新异常 :如果将5级工资的工资数额调为650,则需要找到每个具有5级工资的职工,逐一修改解决之道:分解 模式分解 模式分解的定义 函数依赖集合 F_i = \{\alpha \rightarrow \beta \,|\, \alpha \rightarrow \beta \in F^+ \and (\alpha\, \beta) \subseteq U_i\}称为 F F F U i U_i U i
关系模式 R < U , F > R<U , F> R < U , F > ρ = { R 1 < U 1 , F 1 > , R 2 < U 2 , F 2 > , … , R n < U n , F n > } \rho = \{R_1<U_1 , F_1> , R_2<U_2 , F_2>, … , R_n<U_n , F_n>\} ρ = { R 1 < U 1 , F 1 > , R 2 < U 2 , F 2 > , … , R n < U n , F n > }
其中 U = U 1 ∪ U 2 ∪ … ∪ U n U= U_1 \cup U_2 \cup … \cup U_n U = U 1 ∪ U 2 ∪ … ∪ U n U i ⊆ U j , 1 ≤ i , j ≤ n U_i \subseteq U_j,1≤i,j ≤n U i ⊆ U j , 1 ≤ i , j ≤ n F i F_i F i F F F U i U_i U i
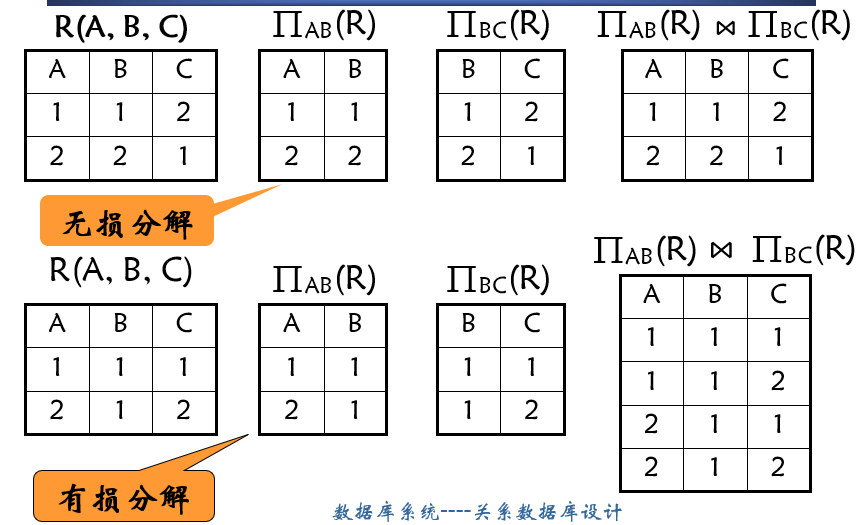
分解的基本代数运算
分解的要求
无损连接分解(分解的底线,必须保证) 保持函数依赖(尽量保持) 模式分解中的问题 有损与无损 原来的关系得不到正确的还原。
函数依赖的保持 某些关系丢失(如 B → C B\rightarrow C B → C
无损连接分解 关系模式 R < U , F > , U = U 1 ∪ U 2 ∪ … ∪ U n R<U , F> , U = U_1 \cup U_2 \cup … \cup U_n R < U , F > , U = U 1 ∪ U 2 ∪ … ∪ U n
ρ = { R 1 < U 1 , F 1 > , R 2 < U 2 , F 2 > , … , R n < U n , F n > } \rho = \{R_1<U_1 , F_1> , R_2<U_2 , F_2>, … , R_n<U_n , F_n>\} ρ = { R 1 < U 1 , F 1 > , R 2 < U 2 , F 2 > , … , R n < U n , F n > } R < U , F > R<U , F> R < U , F > ρ \rho ρ R < U , F > R<U , F> R < U , F > m ρ ( r ) = ⋈ i = 1 n ∏ U i ( r ) m_{\rho}(r) = \overset {n} {\mathop{\bowtie } \limits_{i=1} }∏U_i(r) m ρ ( r ) = i = 1 ⋈ n ∏ U i ( r ) R < U , F > R<U , F> R < U , F > r r r r = m ρ ( r ) r = m_{\rho}(r) r = m ρ ( r ) r r r R < U , F > R<U , F> R < U , F >
无损连接分解判断-表格法 设关系模式 R ( U , F ) , U = A 1 , … , A n R(U,F),U = {A_1,…,A_n} R ( U , F ) , U = A 1 , … , A n R R R ρ = { R 1 , … , R k } \rho = \{R_1,…,R_k\} ρ = { R 1 , … , R k }
构造一张 k k k n n n A j ( 1 ≤ j ≤ n ) A_j(1≤j≤n) A j ( 1 ≤ j ≤ n ) R i ( 1 ≤ i ≤ k ) R_i(1≤i≤k) R i ( 1 ≤ i ≤ k ) A j A_j A j R i R_i R i i i i j j j a j a_j a j b i j b_{ij} b ij
把表格看成模式 R R R F F F f f f
对于 F F F f : α → β f: \alpha \rightarrow \beta f : α → β α \alpha α β \beta β β \beta β β \beta β a j a_j a j a j a_j a j a j a_j a j b i j b_{ij} b ij i j ij ij i i i 若在修改的过程中,发现表格中有一行全是 α \alpha α α 1 , α 2 , … , α n \alpha_1,\alpha_2,…,\alpha_n α 1 , α 2 , … , α n r r r F F F α \alpha α
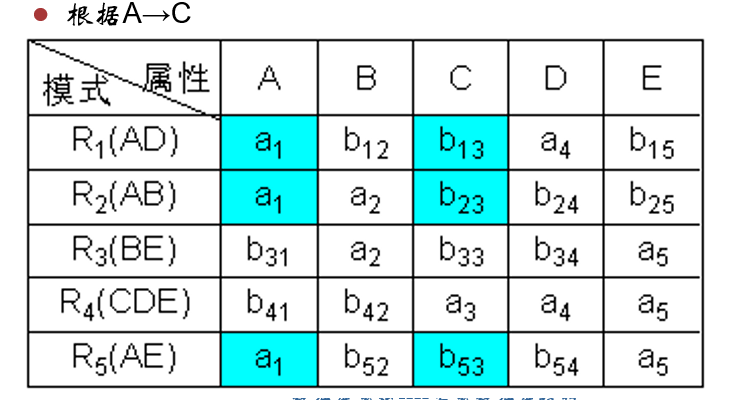
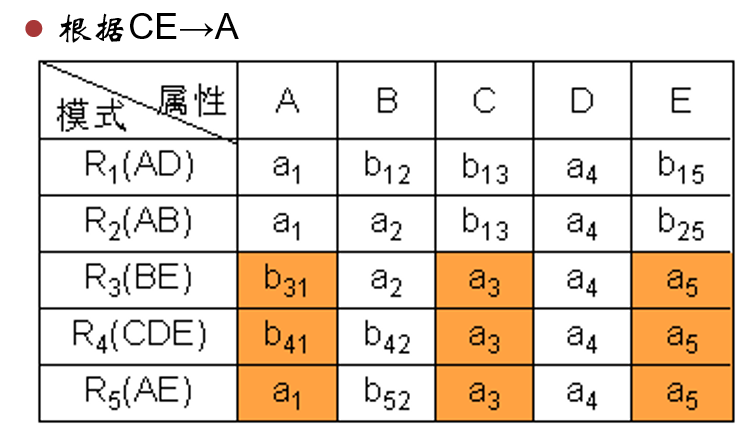
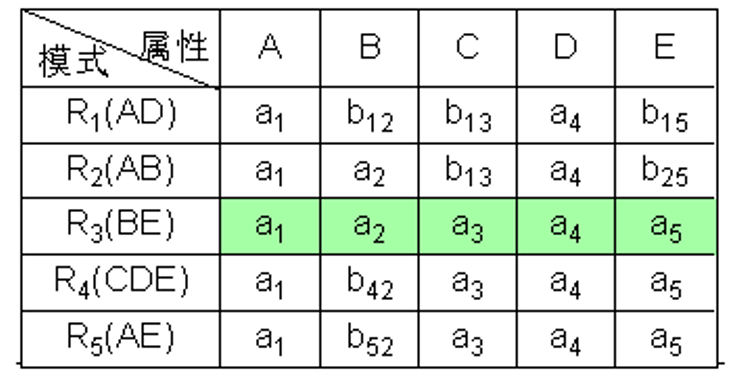
示例 已知 R < U , F > , U = { A , B , C , D , E } , F = { A → C , B → C , C → D , D E → C , C E → A } R<U,F>,U = \{A,B,C,D,E\},F = \{A→C,B→C,C→D,DE→C,CE→A\} R < U , F > , U = { A , B , C , D , E } , F = { A → C , B → C , C → D , D E → C , CE → A } R R R R 1 ( A D ) , R 2 ( A B ) , R 3 ( B E ) , R 4 ( C D E ) , R 5 ( A E ) R_1(AD),R_2(AB),R_3(BE),R_4(CDE),R_5(AE) R 1 ( A D ) , R 2 ( A B ) , R 3 ( BE ) , R 4 ( C D E ) , R 5 ( A E )
表格初始化如上图,对于 A → C A \rightarrow C A → C R 1 , R 2 , R 5 R_1,R_2,R_5 R 1 , R 2 , R 5 A A A a 1 a_1 a 1 C C C a a a b 13 b_{13} b 13
改完后如下。
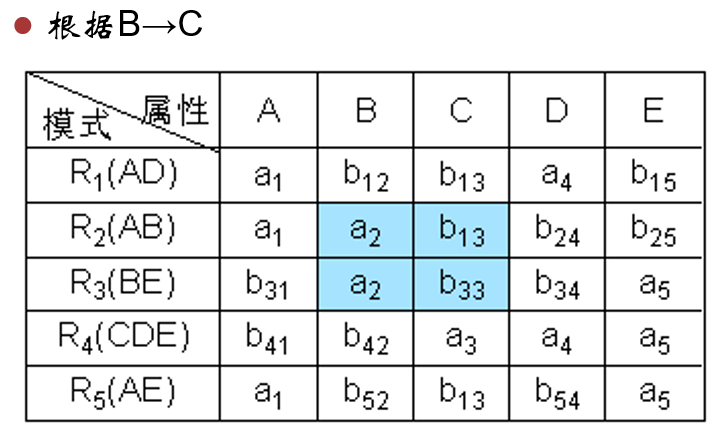
对于 B → C B \rightarrow C B → C R 2 , R 3 R_2,R_3 R 2 , R 3 B B B a 2 a_2 a 2 C C C a a a b 13 b_{13} b 13
改完后如下。
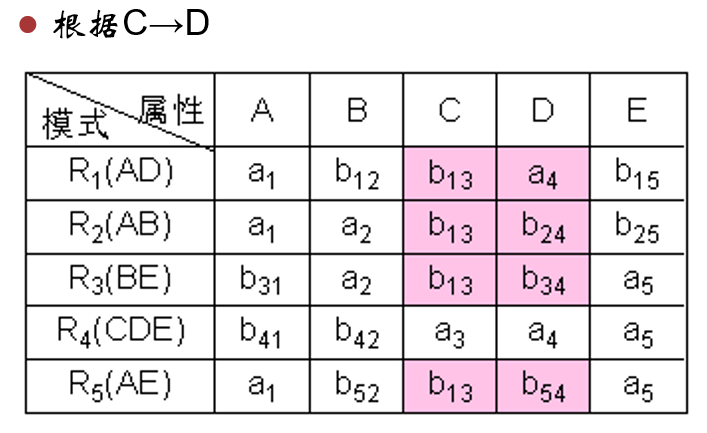
以此类推。
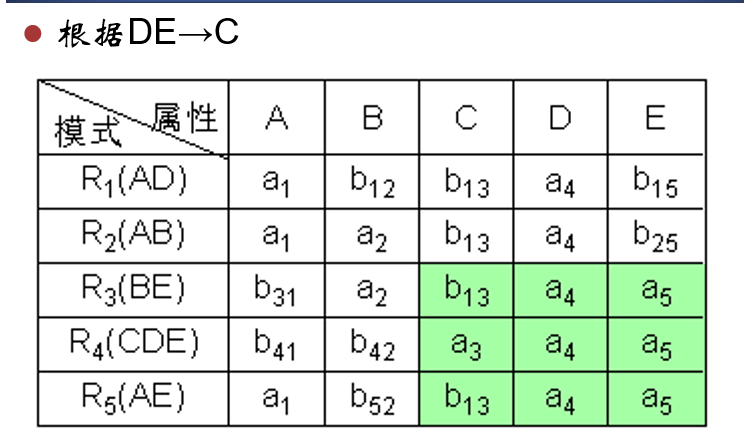
改完后:
说明分解是无损的。
无损连接分解判断-快速法 前提:分解后的关系模式只有两个
在函数依赖约束下,是必要条件 ,可能有多值依赖
关系模式 R ( U , F ) R(U,F) R ( U , F ) ρ = { R 1 , R 2 } \rho=\{R_1,R_2\} ρ = { R 1 , R 2 } ρ \rho ρ R 1 ∩ R 2 → R 1 R_1∩R_2\rightarrow R_1 R 1 ∩ R 2 → R 1 R 1 ∩ R 2 → R 2 R_1∩R_2\rightarrow R_2 R 1 ∩ R 2 → R 2 R 1 ∩ R 2 → R 1 − R 2 R_1∩R_2\rightarrow R_1 - R_2 R 1 ∩ R 2 → R 1 − R 2 R 1 ∩ R 2 → R 2 − R 1 R_1∩R_2\rightarrow R_2 - R_1 R 1 ∩ R 2 → R 2 − R 1
(R 1 , R 2 R_1,R_2 R 1 , R 2
示例 R ( U , F ) , U = { A , B , C } , F = { A → B } , r = { R 1 ( A B ) , R 2 ( A C ) } R(U,F),U = \{A, B, C\}, F=\{A \rightarrow B\}, r=\{R_1(AB), R_2(AC)\} R ( U , F ) , U = { A , B , C } , F = { A → B } , r = { R 1 ( A B ) , R 2 ( A C )}
R 1 ∩ R 2 = A , R 1 - R 2 = B R_1∩R_2 = A, R_1-R_2 = B R 1 ∩ R 2 = A , R 1 - R 2 = B
由 A → B A \rightarrow B A → B ρ \rho ρ
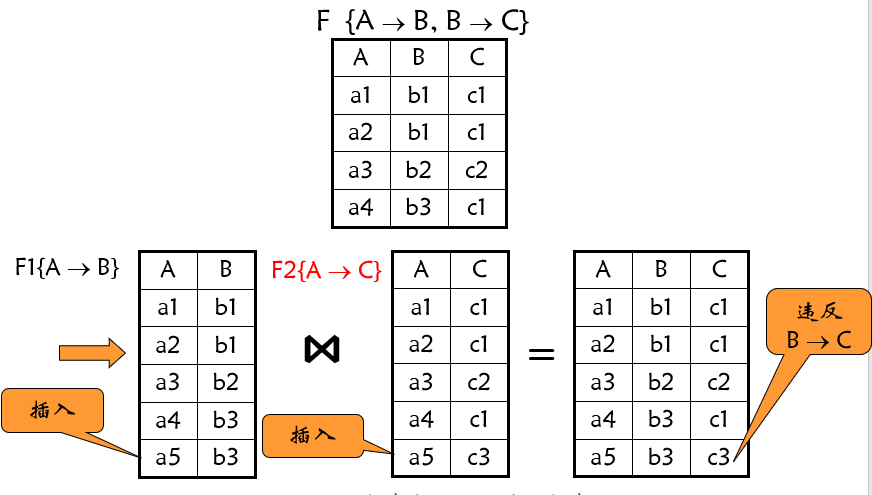
保持函数依赖的分解 给定关系模式 R ( U , F ) R(U,F) R ( U , F ) γ \gamma γ U U U F F F γ \gamma γ
\Pi_{\gamma}(F) =\{\alpha \rightarrow \beta \,|\, \alpha\rightarrow \beta \in F^+ \and \alpha\beta \subseteq \gamma\}设 ρ = { R 1 , R 2 , … , R n } \rho = \{R_1, R_2, …, R_n\} ρ = { R 1 , R 2 , … , R n } R < U , F > R<U , F> R < U , F > F + = ( ∏ R 1 ( F ) ∪ … ∪ ∏ R n ( F ) ) + F^+ = (∏R_1 (F)\cup … \cup ∏R_n (F))^+ F + = ( ∏ R 1 ( F ) ∪ … ∪ ∏ R n ( F ) ) + ρ \rho ρ
判定保持依赖 通过检查 F F F
但是,有时分解是保持依赖的,但是 F F F 。只要 F + = ( ∏ R 1 ( F ) ∪ … ∏ R n ( F ) ) + F^+ = (∏R_1 (F)\cup … ∏R_n (F))^+ F + = ( ∏ R 1 ( F ) ∪ … ∏ R n ( F ) ) +
为了避免计算 F + F^+ F + 通过使用修改后的属性闭包的形式,判断 F F F α → β α\rightarrow β α → β 。
例如对于 R ( U , F ) , U = { A , B , C } , F = { A → B , B → C } R(U,F),U = \{A, B, C\},F= \{A\rightarrow B , B\rightarrow C\} R ( U , F ) , U = { A , B , C } , F = { A → B , B → C } ρ { < { A B } , { A → B } > , < { A C } , { A → C } > } \rho\{<\{AB\},\{A\rightarrow B\}>,<\{AC\},\{A\rightarrow C\}>\} ρ { < { A B } , { A → B } > , < { A C } , { A → C } > }
我们只需要判断:B → C ∈ { A → B , A → C } + B\rightarrow C\in \{A\rightarrow B, A\rightarrow C\}^+ B → C ∈ { A → B , A → C } +
也就是判断 C ∈ B { A → B , A → C } + C\in B^+_{\{A\rightarrow B, A\rightarrow C\}} C ∈ B { A → B , A → C } + B B B C C C
算法 模式分解示例 示例1:设关系模式 R < U , F > R<U, F> R < U , F > U = { A , B , C , D , E } , F = { A → B C , C → D , B C → E , E → A } U=\{A, B, C, D, E\},F=\{A→BC,C→D,BC→E,E→A\} U = { A , B , C , D , E } , F = { A → BC , C → D , BC → E , E → A } ρ = { R 1 ( A B C E ) , R 2 ( C D ) } ρ=\{R_1(ABCE),R_2(CD)\} ρ = { R 1 ( A BCE ) , R 2 ( C D )}
–A.具有无损连接性、保持函数依赖
–B.不具有无损连接性、保持函数依赖
–C.具有无损连接性、不保持函数依赖
–D.不具有无损连接性、不保持函数依赖
A
示例2:给定关系模式 R < U , F > , U = { A , B , C , D , E } , F = { B → A , D → A , A → E , A C → B } R<U, F>,U=\{A, B, C, D, E\},F=\{B→A,D→A,A→E,AC→B\} R < U , F > , U = { A , B , C , D , E } , F = { B → A , D → A , A → E , A C → B } ρ = { R 1 ( A B C E ) , R 2 ( C D ) } ρ=\{R_1(ABCE),R_2(CD)\} ρ = { R 1 ( A BCE ) , R 2 ( C D )}
候选码为 C D CD C D
B → A , A → E , A C → B B→A,A→E,AC→B B → A , A → E , A C → B R 1 R_1 R 1 D → A D→A D → A R 1 R_1 R 1 R 2 R_2 R 2
对于 D → A D→A D → A
Result = D
对R 1 R_1 R 1 r e s u l t ∩ R 1 = ∅ result∩R_1 = \emptyset res u lt ∩ R 1 = ∅ t t t ∅ \emptyset ∅
再对 R 2 R_2 R 2 r e s u l t ∩ R 2 = D result∩R_2 = D res u lt ∩ R 2 = D ( D ) + = { A D E } , t = ( D ) + ∩ R 2 = D (D)^+ = \{ADE\} ,t = (D)^+ ∩R_2 = D ( D ) + = { A D E } , t = ( D ) + ∩ R 2 = D
一个循环后result未发生变化,因此最后result = D,并未包含 A A A D → A D→A D → A
示例3:给定关系模式 R ( U , F ) , U = { A , B , C , D , E , F } , F = { A → B C , C D → E , B → D , B E → F , E F → A } R(U, F),U =\{A,B,C,D,E,F\},F = \{A → BC, CD → E, B → D, BE → F, EF → A\} R ( U , F ) , U = { A , B , C , D , E , F } , F = { A → BC , C D → E , B → D , BE → F , EF → A } ρ = { R 1 ( A B C D ) , R 2 ( E F A ) } ρ= \{R_1(ABCD),R_2(EFA)\} ρ = { R 1 ( A BC D ) , R 2 ( EF A )}
判断无损连接分解:R 1 ∩ R 2 = { A } , A F + = { A , B , C , D , E , F } R_1 ∩ R_2 = \{A\},A^+_F = \{A, B, C, D, E, F\} R 1 ∩ R 2 = { A } , A F + = { A , B , C , D , E , F } A → R 1 A → R_1 A → R 1
判断保持依赖的分解:观察 C D → E CD → E C D → E B E → F BE → F BE → F C D → E CD → E C D → E B E → F BE → F BE → F
示例4:给定关系模式 R ( U , F ) , U = { A , B , C , D , E , F } , F = { A → B C , C D → E , B → D , B E → F , E F → A } R(U, F),U =\{A,B,C,D,E,F\},F = \{A → BC, CD → E, B → D, BE → F, EF → A\} R ( U , F ) , U = { A , B , C , D , E , F } , F = { A → BC , C D → E , B → D , BE → F , EF → A } ρ = { ( A B C ) , ( B D ) , ( B E F ) } ρ = \{(ABC),(BD),(BEF)\} ρ = {( A BC ) , ( B D ) , ( BEF )}
非无损
判断保持依赖的分解:观察 C D → E CD → E C D → E E F → A EF →A EF → A C D → E CD → E C D → E E F → A EF → A EF → A
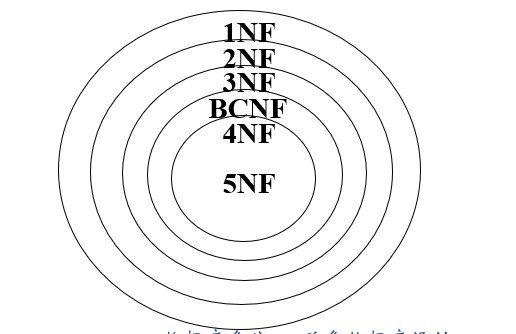
范式 范式(1NF等)指该范式的定义,同时也代表满足该范式的关系模式的集合,比如 2 N F ⊂ 1 N F , R ∈ 1 N F 2NF \subset 1NF,R\in 1NF 2 NF ⊂ 1 NF , R ∈ 1 NF
1NF 关系中每一分量不可再分。即不能以集合、序列等作为属性值。
2NF 样例 关系模式 S ( s n o , s n a m e , d n o , d e a n , c n o , s c o r e ) S(sno, sname, dno, dean, cno, score) S ( s n o , s nam e , d n o , d e an , c n o , score )
主码:sno, cno
不良特性插入异常:如果学生没有选课,关于他的个人信息及所在学院的信息就无法插入 删除异常:如果删除学生的选课信息,则有关他的个人信息及所在学院的信息也随之删除 更新异常:如果学生转专业,若他选修了k门课,则需要修改k次 数据冗余:如果一个学生选修了k门课,则有关他的所在学院的信息重复 改造 属性有两种,一种完全依赖于候选码,一种部分依赖于候选码。
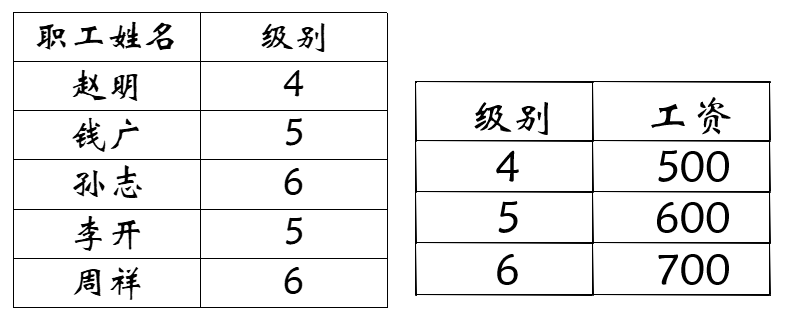
将S分解为:
S C ( s n o , c n o , s c o r e ) SC(sno , cno , score) SC ( s n o , c n o , score ) s n o , c n o sno,cno s n o , c n o
S _ S D ( s n o , s n a m e , d n o , d e a n ) S\_SD(sno, sname, dno, dean) S _ S D ( s n o , s nam e , d n o , d e an ) s n o sno s n o
定义 若 R ∈ 1 N F R\in 1NF R ∈ 1 NF
它出现在一个候选码中 它没有部分依赖于一个候选码 (也就是说不存在候选码的一部分决定该属性的情况)则 R ∈ 2 N F R\in 2NF R ∈ 2 NF
核心就是消除非主属性对候选码的部分依赖
上面的例子中,s n a m e , d n o sname,dno s nam e , d n o
3NF 样例 S _ S D ( s n o , s n a m e , d n o , d e a n ) S\_SD(sno, sname, dno, dean) S _ S D ( s n o , s nam e , d n o , d e an )
不良特性插入异常:如果学院没有学生,则有关学院的信息就无法插入 删除异常:如果学生全部毕业了,则在删除学生信息的同时有关学院的信息也随之删除了 更新异常:如果学生转专业,不但要修改dno,还要修改dean,如果换院长,则该学院每个学生元组都要做相应修改 数据冗余:每个学生存储了所在院长的信息 S S D ∉ 3 N F S_SD \not \in3NF S S D ∈ 3 NF s n o → d n o , d n o → d e a n sno\rightarrow dno,dno\rightarrow dean s n o → d n o , d n o → d e an
改造 将S_SD分解为 S ( s n o , s n a m e , d n o ) S (sno, sname, dno) S ( s n o , s nam e , d n o ) D ( d n o , d e a n ) D (dno, dean) D ( d n o , d e an )
定义 关系模式 R < U , F > R<U , F> R < U , F > F + F^+ F + α → β α\rightarrow β α → β 至少有以下之一成立 :
α → β α\rightarrow β α → β 平凡的函数依赖 ;α α α 超码 ;β − α β - α β − α 每一个属性 A A A R R R 候选码 中,则称 R ∈ 3 N F R\in 3NF R ∈ 3 NF 注意:并不要求集合之差在同一个 候选码当中 注意候选码是要保证完全依赖的,否则是超码 关系模式 R < U , F > R< U , F > R < U , F > X X X Y Y Y 非主属性 Z ( Z ⊄ Y ) Z(Z \not \sub Y) Z ( Z ⊂ Y ) X → Y , Y → Z , Y ↛ X X\rightarrow Y , Y\rightarrow Z , Y\not\rightarrow X X → Y , Y → Z , Y → X R ∈ 3 N F R\in 3NF R ∈ 3 NF
主属性:包含在候选码 中的属性 即 R R R Z Z Z R R R PS.作为判断3NF时的一种优化,可以只考虑 F F F F + F^+ F + F F F F F F
关系模式分解算法 简单算法 分解后的关系要达到3NF且保持函数依赖的分解
输入:关系模式 R ( U , F ) R(U,F) R ( U , F )
计算 F F F 正则覆盖 F c F_c F c
若有 α → β ∈ F c α\rightarrow β\in F_c α → β ∈ F c α ∪ β = U α\cup β = U α ∪ β = U
对 F c F_c F c 相同左部 的原则进行分组 (设为k组),每一组函数依赖所涉及的属性全体为 U i U_i U i F i F_i F i F c F_c F c U i U_i U i 投影 ,则 ρ = { R 1 < U 1 , F 1 > , … , R k < U k , F k > } \rho = \{R_1<U_1 , F_1> , … , R_k<U_k , F_k>\} ρ = { R 1 < U 1 , F 1 > , … , R k < U k , F k > } R < U , F > R<U , F> R < U , F > R i < U i , F i > ∈ 3 N F R_i<U_i , F_i> \in 3NF R i < U i , F i >∈ 3 NF
返回 ρ \rho ρ
示例1 R ( U , F ) , U = { s n o , d n o , d e a n , c n o , s c o r e } R(U,F),U=\{sno,dno,dean,cno,score\} R ( U , F ) , U = { s n o , d n o , d e an , c n o , score }
F = { s n o → d n o , s n o → d e a n , d n o → d e a n , ( s n o , c n o ) → s c o r e } F=\{sno\rightarrow dno,sno\rightarrow dean,dno\rightarrow dean,(sno,cno)\rightarrow score\} F = { s n o → d n o , s n o → d e an , d n o → d e an , ( s n o , c n o ) → score }
F C = { s n o → d n o , d n o → d e a n , ( s n o , c n o ) → s c o r e } F_C=\{sno\rightarrow dno,dno\rightarrow dean ,(sno,cno)\rightarrow score\} F C = { s n o → d n o , d n o → d e an , ( s n o , c n o ) → score }
分组
R 1 { ( s n o , d n o ) , s n o → d n o } R_1 \{(sno,dno),sno\rightarrow dno\} R 1 {( s n o , d n o ) , s n o → d n o }
R 2 { ( d n o , d e a n ) , d n o → d e a n } R_2 \{(dno,dean),dno\rightarrow dean\} R 2 {( d n o , d e an ) , d n o → d e an }
R 3 { ( s n o , c n o , s c o r e ) , ( s n o , c n o ) → s c o r e } R_3 \{(sno,cno,score), (sno,cno)\rightarrow score\} R 3 {( s n o , c n o , score ) , ( s n o , c n o ) → score }
可以验证,这是无损分解。
显然候选码是AB,因为这两个是L类属性而C是R类属性。
由于A或B都不是超码,而且C不在候选码中,所以不属于3NF。
R 1 ∩ R 2 = { A } , A → C , A → R 1 R_1\cap R_2=\{A\},A\rightarrow C,A\rightarrow R_1 R 1 ∩ R 2 = { A } , A → C , A → R 1
解决上面的问题:3NF合成算法 输入关系模式 R ( U , F ) R(U,F) R ( U , F )
1、ρ = { R 1 < U 1 , F 1 > , … , R k < U k , F k > } \rho = \{R_1<U_1 , F_1> , … , R_k<U_k , F_k>\} ρ = { R 1 < U 1 , F 1 > , … , R k < U k , F k > } R < U , F > R<U , F> R < U , F > 保持函数依赖 的3NF分解
2、设 α \alpha α R < U , F > R<U , F> R < U , F > 任意候选码 ,若有某个 U i U_i U i α ⊆ U i \alpha \subseteq U_i α ⊆ U i ρ \rho ρ τ = ρ ∪ { R ∗ < α , F α > } τ = \rho∪\{R* < \alpha ,F_{\alpha}>\} τ = ρ ∪ { R ∗ < α , F α > }
返回 τ τ τ
教材算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 令Fc为F的一个正则覆盖 i = 0 for each Fc中的函数依赖α-β(用-代替右箭头) i := i + 1; Ri := αβ; if 模式Rj, j = 1,2,…,i 都不包含R的候选码 then i := i + 1; Ri := R的任意候选码; repeat/*删除冗余关系模式*/ //下面是相对上面算法多出的部分 if 模式 Rj 包含于另一个模式Rk中 then Rj := Ri; i := i – 1; Until 没有可以删除的Rj return (R1,R2,…Ri)
算法比较
合成算法的算法正确性分析 三个条件:保持依赖、无损、分解结果的关系是3NF
保持依赖 无损连接 通过保证至少有一个模式包含了被分解模式的候选码 ,该算法保证了分解是一个无损连接分解。证明如下:
注意:有损分解一定是多了一些元组。
那么就不存在这样的 t t t
注意第三点:元组t t t r r r t [ α ] ∈ r i t[\alpha]\in r_i t [ α ] ∈ r i 每个关系模式都是3NF 如果关系模式 R i R_i R i R i ∈ 3 N F R_i∈3NF R i ∈ 3 NF R i R_i R i γ → B \gamma \rightarrow B γ → B B B B
假定综合算法中产生 R i R_i R i α → β ( α → β ∈ F c ) α\rightarrow β (α\rightarrow β ∈ F_c) α → β ( α → β ∈ F c ) U i = α β U_i=\alpha\beta U i = α β B ∈ R i B∈ R_i B ∈ R i B ∈ α B∈α B ∈ α B ∈ β B∈β B ∈ β
B ∈ α ∧ B ∈ β B∈α∧B∈β B ∈ α ∧ B ∈ β β β β A B → B C AB \rightarrow BC A B → BC α → β α\rightarrow β α → β F c F_c F c
B ∉ α ∧ B ∈ β B\not\in α∧B∈β B ∈ α ∧ B ∈ β
γ \gamma γ R i ∈ 3 N F R_i∈3NF R i ∈ 3 NF 注意到 α \alpha α R i R_i R i R i R_i R i α \alpha α γ \gamma γ α α α γ \gamma γ γ → B \gamma \rightarrow B γ → B F + F^+ F + B ∈ γ F c + B∈ \gamma^+_{F_c} B ∈ γ F c + γ → B \gamma \rightarrow B γ → B α → β α\rightarrow β α → β α ∈ γ F c + α∈ \gamma^ +_{F_c} α ∈ γ F c + γ \gamma γ α → β α\rightarrow β α → β γ → α \gamma\rightarrow \alpha γ → α γ \gamma γ α → ( β − { B } ) α\rightarrow (β- \{B\}) α → ( β − { B }) γ → B \gamma \rightarrow B γ → B α → B α\rightarrow B α → B B B B α → β α\rightarrow β α → β α → β α\rightarrow β α → β F c F_c F c B ∈ β B∈β B ∈ β γ \gamma γ B ∈ α ∧ B ∉ β B∈ α∧B \not\in β B ∈ α ∧ B ∈ β α α α
示例 设有关系模式 R ( U , F ) , U = { A B C D E F G H I } , F = { A B → C , A → D E , B → G H , D → I } R(U,F),U= \{ABCDEFGHI\},F=\{AB→C,A→DE,B→GH,D→I\} R ( U , F ) , U = { A BC D EFG H I } , F = { A B → C , A → D E , B → G H , D → I }
R R R
将 R R R
1.候选码:ABF
2.首先求出F的正则覆盖F c = { A B → C , A → D E , B → G H , D → I } , F_c=\{AB→C,A→DE,B→GH,D→I\}, F c = { A B → C , A → D E , B → G H , D → I } ,
得了 τ = ( { A B C } , { A D E } , { B G H } , { D I } , { A B F } ) τ =(\{ABC\}, \{ADE\}, \{BGH\}, \{DI\}, \{ABF\}) τ = ({ A BC } , { A D E } , { BG H } , { D I } , { A BF })
BCNF 样例 关系模式 S T C ( U , F ) STC(U,F) STC ( U , F )
U = { s n o , t n o , c n o } U=\{sno , tno , cno\} U = { s n o , t n o , c n o }
F = { t n o → c n o , ( s n o , t n o ) → c n o , ( s n o , c n o ) → t n o } F=\{tno \rightarrow cno, (sno,tno)\rightarrow cno, (sno,cno)\rightarrow tno\} F = { t n o → c n o , ( s n o , t n o ) → c n o , ( s n o , c n o ) → t n o }
( s n o , t n o ) , ( s n o , c n o ) (sno,tno),(sno,cno) ( s n o , t n o ) , ( s n o , c n o )
不良特性 插入异常:如果没有学生选修某位老师的任课,则该老师担任课程的信息就无法插入
删除异常:删除学生选课信息,会删除掉老师的任课信息
更新异常:如果老师所教授的课程有所改动,则所有选修该老师课程的学生元组都要做改动
数据冗余:每位学生都存储了有关老师所教授的课程的信息
原因
改造
将STC分解为:( s n o , t n o ) , ( t n o , c n o ) (sno,tno),(tno,cno) ( s n o , t n o ) , ( t n o , c n o )
定义 关系模式 R < U , F > R< U , F > R < U , F > α → β α\rightarrow β α → β ( α ⊆ U , β ⊆ U ) ( α\subseteq U,β\subseteq U ) ( α ⊆ U , β ⊆ U )
如 S T C ∉ B C N F STC \not\in BCNF STC ∈ BCNF t n o → c n o tno \rightarrow cno t n o → c n o t n o tno t n o
BCNF的本质 判断关系模式是否属于BCNF 检查非平凡的函数依赖 α → β α\rightarrow β α → β α + α^+ α + R R R α α α R R R
检查关系模式 R R R F F F F + F^+ F + F F F F + F^+ F + 当关系模式被分解后,需要根据 F + F^+ F + R i R_i R i
例如:R ( U , F ) , U = { A B C D E } , F = { A → B , B C → D } 。将 R 分解为 R 1 和 R 2 , U 1 = { A B } , U 2 = { A C D E } R(U,F),U = \{ABCDE\}, F = \{A \rightarrow B, BC \rightarrow D\}。将R分解为R1和R2,U1 =\{AB\},U2 = \{ACDE\} R ( U , F ) , U = { A BC D E } , F = { A → B , BC → D } 。将 R 分解为 R 1 和 R 2 , U 1 = { A B } , U 2 = { A C D E }
R 2 R_2 R 2 F F F A C → D ∈ F + AC \rightarrow D∈F^+ A C → D ∈ F + R 2 R_2 R 2
因此,计算分解后的关系模式是否属于BCNF是NP的
分解算法 注意 此算法只能产生无损连接分解,若要求分解保持函数依赖,那么分解后的模式总可以达到3NF,但不一定能达到BCNF
当我们用 ( R i − β ) (R_i - β) ( R i − β ) ( α β ) (αβ) ( α β ) R i R_i R i α → β α\rightarrow β α → β ( R i − β ) ∩ ( α β ) = α (R_i - β) ∩ (αβ)=α ( R i − β ) ∩ ( α β ) = α
如果我们没有要求 α ∩ β = ∅ α\cap β=\emptyset α ∩ β = ∅ α ∩ β α∩β α ∩ β ( R i − β ) (R_i - β) ( R i − β ) α → β α\rightarrow β α → β
如果 α ∩ β < > ∅ α∩β<>\emptyset α ∩ β <> ∅ α α α { A , B , C } \{A,B,C\} { A , B , C } β β β { C , D , E } \{C,D,E\} { C , D , E } R i R_i R i { A , B , C , D , E , F , G } \{A,B,C,D,E,F,G\} { A , B , C , D , E , F , G } R i – β = { A , B , F , G } R_i – β=\{A,B,F,G\} R i – β = { A , B , F , G } α β = { A , B , C , D , E } αβ=\{A,B,C,D,E\} α β = { A , B , C , D , E } ( R i – β ) ∩ ( α β ) = { A , B } ( R_i – β)∩ (αβ)=\{A,B\} ( R i – β ) ∩ ( α β ) = { A , B } ( R i – β ) ∩ ( α β ) → β ( R_i – β)∩ (αβ) \rightarrow β ( R i – β ) ∩ ( α β ) → β
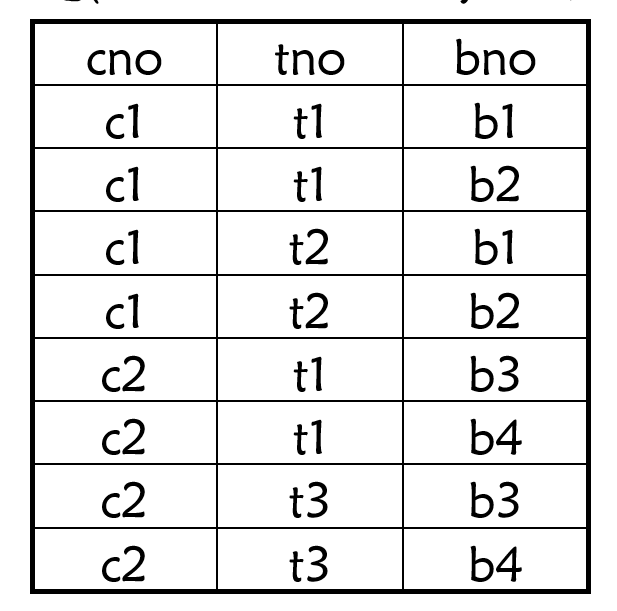
多值依赖 样例 关系模式 T E A C H ( c n o , t n o , b n o ) TEACH(cno,tno,bno) TE A C H ( c n o , t n o , bn o ) ( c n o , t n o , b n o ) (cno,tno,bno) ( c n o , t n o , bn o )
不良特性 插入异常:当某门课程增加一名教师时,该门课程有多少本参考书就必须插入多少个元组;同样当某门课程需要增加一本参考书时,它有多少个教师就必须插入多少个元组
删除异常:当删除一门课程的某个教师或者某本参考书时,需要删除多个元组
更新异常:当一门课程的教师或参考书作出改变时,需要修改多个元组
数据冗余:同一门课的教师与参考书的信息被反复存储多次
定义 描述型 :关系模式 R ( U ) R(U) R ( U ) α 、 β 、 γ ⊂ U \alpha、\beta、\gamma \subset U α 、 β 、 γ ⊂ U γ = U – α – β \gamma = U – \alpha – \beta γ = U – α – β α → → β \alpha \rightarrow\rightarrow \beta α →→ β R ( U ) R(U) R ( U ) r r r ( α 1 , γ 1 ) (\alpha_1,\gamma_1) ( α 1 , γ 1 ) β \beta β α \alpha α γ \gamma γ 注意,是”有一组 β \beta β 如在关系模式TEACH中,对(c1 , b1)有一组tno值(t1 , t2),对(c1 , b2)也有一组tno值(t1 , t2),这组值仅取决于cno的取值,而与bno的取值无关。因此,tno多值依赖于cno,记作 c n o → → t n o cno\rightarrow \rightarrow tno c n o →→ t n o c n o → → b n o cno\rightarrow \rightarrow bno c n o →→ bn o
形式化 :关系模式 R ( U ) R(U) R ( U ) α 、 β 、 γ ⊂ U \alpha、\beta、\gamma \subset U α 、 β 、 γ ⊂ U γ = U – α – β \gamma = U – \alpha – \beta γ = U – α – β R ( U ) R(U) R ( U ) r r r t 1 , t 2 t1,t2 t 1 , t 2 t 1 [ α ] = t 2 [ α ] t1[\alpha] = t2[\alpha] t 1 [ α ] = t 2 [ α ] t 3 , t 4 t3,t4 t 3 , t 4 t 3 [ α ] = t 4 [ α ] = t 1 [ α ] = t 2 [ α ] t3[\alpha] = t4[\alpha] = t1[\alpha] = t2[\alpha] t 3 [ α ] = t 4 [ α ] = t 1 [ α ] = t 2 [ α ]
t 3 [ β ] = t 1 [ β ] , t 3 [ γ ] = t 2 [ γ ] t3[\beta] = t1[\beta], t3[\gamma] = t2[\gamma] t 3 [ β ] = t 1 [ β ] , t 3 [ γ ] = t 2 [ γ ]
t 4 [ β ] = t 2 [ β ] , t 4 [ γ ] = t 1 [ γ ] t4[\beta] = t2[\beta] , t4[\gamma] = t1[\gamma] t 4 [ β ] = t 2 [ β ] , t 4 [ γ ] = t 1 [ γ ]
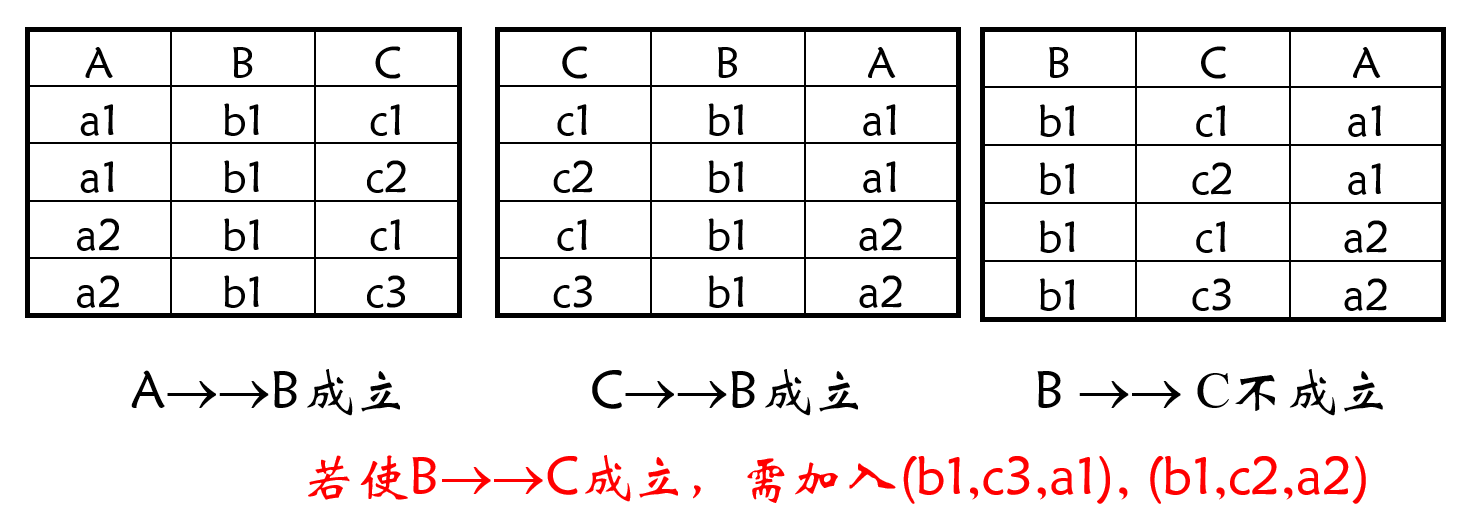
则称 β \beta β α \alpha α
性质 多值依赖具有对称性,即:若α → → β \alpha \rightarrow \rightarrow \beta α →→ β α → → γ \alpha\rightarrow \rightarrow \gamma α →→ γ γ = U – α – β \gamma =U–\alpha–\beta γ = U – α – β
函数依赖是多值依赖的特例,即:若 α → β \alpha \rightarrow \beta α → β α → → β \alpha\rightarrow \rightarrow \beta α →→ β
若 α → → β \alpha \rightarrow \rightarrow \beta α →→ β U – α – β = ∅ U\,–\,\alpha\,–\,\beta=\emptyset U – α – β = ∅ β ⊆ α \beta \subseteq \alpha β ⊆ α α → → β \alpha\rightarrow \rightarrow \beta α →→ β
多值依赖具有传递性,若 α → → β , β → → γ \alpha →→ \beta , \beta →→ \gamma α →→ β , β →→ γ α → → γ – β \alpha →→ \gamma\, –\, \beta α →→ γ – β
若 α → → β , α → → γ \alpha →→ \beta ,\alpha →→ \gamma α →→ β , α →→ γ α → → β ∪ γ \alpha →→ \beta \cup \gamma α →→ β ∪ γ
若 α → → β , α → → γ \alpha →→ \beta ,\alpha →→ \gamma α →→ β , α →→ γ α → → β ∩ γ \alpha →→ \beta ∩ \gamma α →→ β ∩ γ
若 α → → β , α → → γ \alpha →→ \beta ,\alpha →→ \gamma α →→ β , α →→ γ α → → β − γ , α → → γ − β \alpha →→ \beta - \gamma ,\alpha →→ \gamma - \beta α →→ β − γ , α →→ γ − β
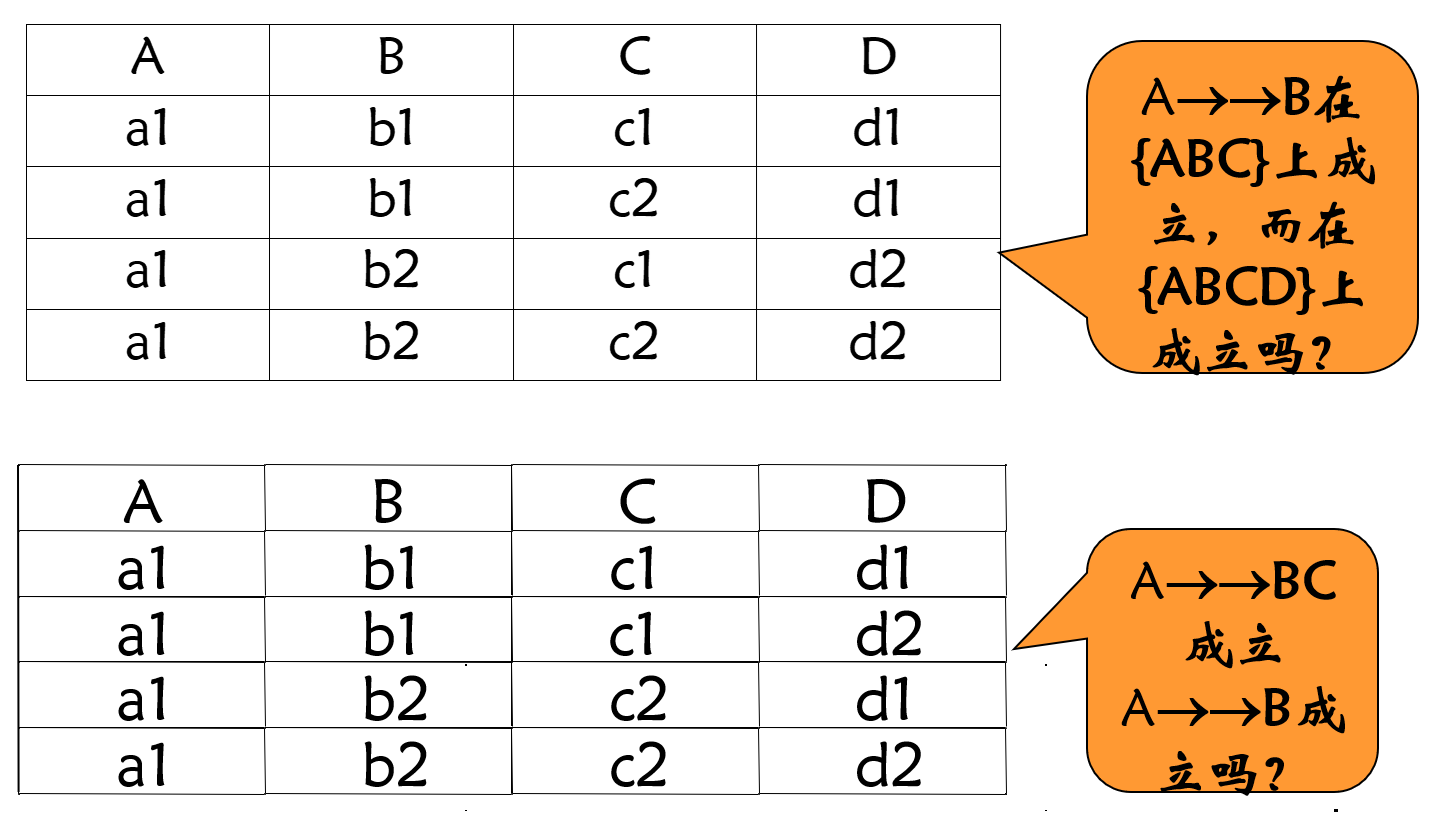
举例 多值依赖与函数依赖 区别 有效性范围 α → β \alpha \rightarrow \beta α → β α 、 β \alpha 、 \beta α 、 β W ( α β ⊆ W ⊆ U ) W( \alpha\beta \subseteq W \subseteq U) W ( α β ⊆ W ⊆ U ) α → β \alpha \rightarrow \beta α → β R ( U ) R(U) R ( U ) β ′ ⊆ β \beta' \subseteq \beta β ′ ⊆ β α → β ′ \alpha \rightarrow \beta' α → β ′
α → → β \alpha \rightarrow\rightarrow \beta α →→ β
α → → β \alpha \rightarrow\rightarrow \beta α →→ β W ( α β ⊆ W ⊆ U ) W( \alpha\beta \subseteq W \subseteq U) W ( α β ⊆ W ⊆ U ) U U U
α → → β \alpha \rightarrow\rightarrow \beta α →→ β U U U α → → β \alpha \rightarrow\rightarrow \beta α →→ β W ( α β ⊆ W ⊆ U ) W( \alpha\beta \subseteq W \subseteq U) W ( α β ⊆ W ⊆ U )
若α → → β \alpha \rightarrow\rightarrow \beta α →→ β R ( U ) R(U) R ( U ) β ′ ⊆ β \beta'\subseteq \beta β ′ ⊆ β α → → β ′ \alpha \rightarrow\rightarrow \beta' α →→ β ′
都不成立。
闭包 令 D D D D D D D + D^+ D + D D D 函数依赖和多值依赖 的集合
我们可以用函数依赖和多值依赖的形式化定义由 D D D D + D^+ D +
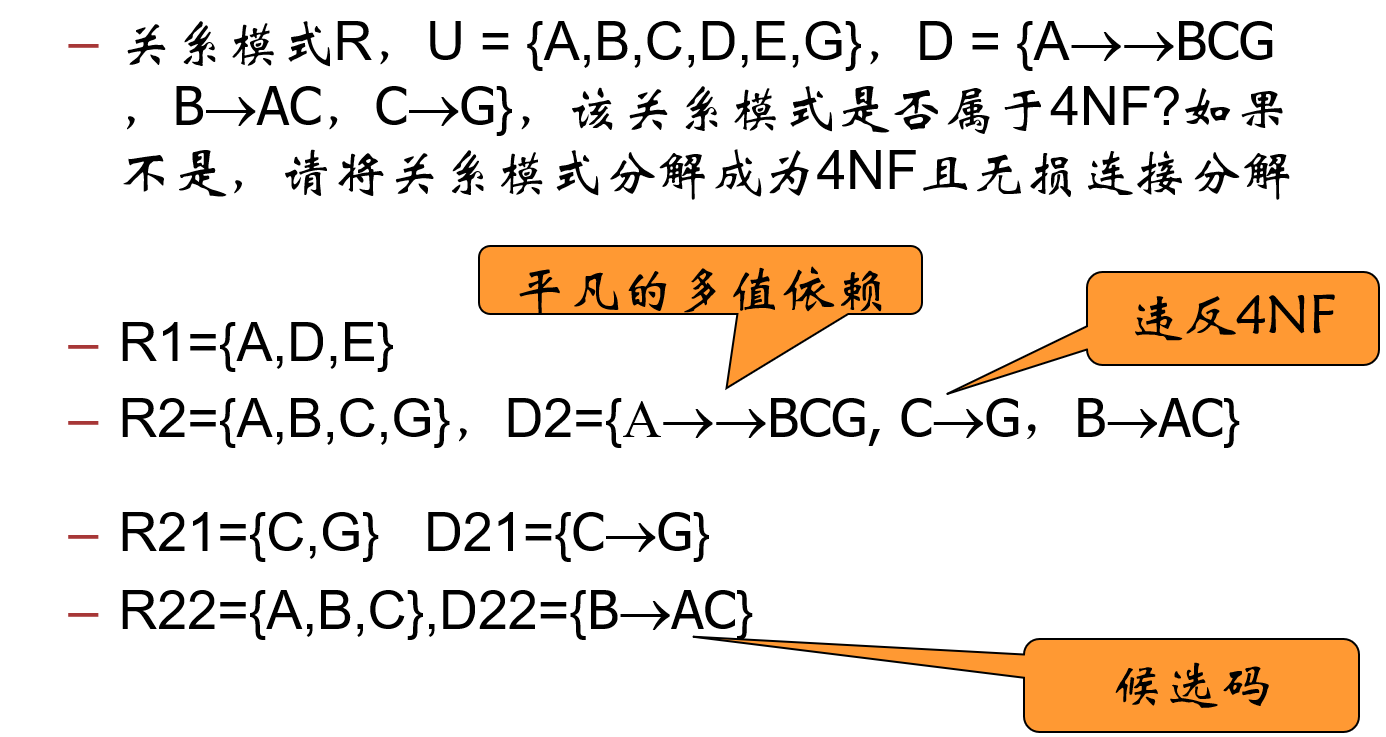
4NF 定义 函数依赖和多值依赖集为 D D D R R R D + D^+ D + α → → β \alpha \rightarrow\rightarrow \beta α →→ β α ⊆ R ∧ β ⊆ R α\subseteq R∧ β\subseteq R α ⊆ R ∧ β ⊆ R
α → → β \alpha \rightarrow\rightarrow \beta α →→ β 平凡的多值依赖 ;α α α R R R 超码 。示例 R 1 R_1 R 1 R 2 R_2 R 2 R 3 R_3 R 3 R 4 , R 5 R_4,R_5 R 4 , R 5
4NF的本质 (在只考虑函数和多值依赖的前提下) 4NF只讲一件事,非码的多值决定关系讲述了另外一件事
证明 4 N F ⊂ B C N F 4NF \subset BCNF 4 NF ⊂ BCNF 假设 R ∈ 4 N F , R ∉ B C N F R \in 4NF,R \not\in BCNF R ∈ 4 NF , R ∈ BCNF R ∉ B C N F R \not\in BCNF R ∈ BCNF α → β α→β α → β α α α α → β α→β α → β α → → β α→→ β α →→ β R ∉ 4 N F R \not\in 4NF R ∈ 4 NF
又:存在 R ( D ) ∈ B C N F , R ( D ) ∈ 4 N F R(D)\in BCNF,R(D)\in 4NF R ( D ) ∈ BCNF , R ( D ) ∈ 4 NF
关系模式的分解算法-4NF D D D R i R_i R i D i D_i D i
示例 小结 1NF:数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。
2NF:1NF的基础上,非码属性必须完全依赖于码。在1NF基础上消除非主属性对主码的部分函数依赖
3NF:在1NF基础上,任何非主属性不依赖于其它非主属性。在2NF基础上消除传递依赖。
BCNF:在1NF基础上,任何非主属性不能对主键子集依赖,在3NF基础上消除对主码子集的依赖
4NF:在多值依赖的视角评价关系模式
时态数据建模 时态数据是与时间段有关的数据,该时间段表明数据有效的时间。数据快照表示一个特定时间点上该数据的值。在特定时间点上成立的函数依赖称为时态函数依赖。
时态函数依赖在常规的函数依赖中很难推理。
习题课 分解为BCNF 一 R ( U , F ) : U = { A B C D } , F = { A B → C , C → D , D → A } R(U,F):U=\{ABCD\},F=\{AB \rightarrow C,C\rightarrow D,D\rightarrow A\} R ( U , F ) : U = { A BC D } , F = { A B → C , C → D , D → A }
显然 C → D , D → A C \rightarrow D,D \rightarrow A C → D , D → A R 1 ( C D ) , R 2 ( A B C ) R_1(CD),R_2(ABC) R 1 ( C D ) , R 2 ( A BC )
对应到算法之中,此时 R i = R = r e s u l t R_i=R=result R i = R = res u lt r e s u l t − R i = ∅ result-R_i=\emptyset res u lt − R i = ∅
注意到 R 2 R_2 R 2 C → A ∈ F + C \rightarrow A\in F^+ C → A ∈ F + R 2 ( A B C ) R_2(ABC) R 2 ( A BC ) R 21 ( C A ) , R 22 ( C B ) R_{21}(CA),R_{22}(CB) R 21 ( C A ) , R 22 ( CB )
(当然也可以先将 D → A D\rightarrow A D → A
二 R ( U , F ) : U = { A B C D } , F = { B → C , B → D } R(U,F):U=\{ABCD\},F=\{B \rightarrow C,B\rightarrow D\} R ( U , F ) : U = { A BC D } , F = { B → C , B → D }
B → C , B → D B \rightarrow C,B\rightarrow D B → C , B → D B → C B\rightarrow C B → C R 1 ( B C ) , R 2 ( A B D ) R_1(BC),R_2(ABD) R 1 ( BC ) , R 2 ( A B D ) B → D B \rightarrow D B → D R 2 R_2 R 2 R 21 ( B D ) , R 22 ( A D ) R_{21}(BD),R_{22}(AD) R 21 ( B D ) , R 22 ( A D )
三 R ( U , F ) : U = { A B C D } , F = { A B → C , B C → D , C D → A , A D → B } R(U,F):U=\{ABCD\},F=\{AB \rightarrow C,BC\rightarrow D,CD\rightarrow A,AD \rightarrow B\} R ( U , F ) : U = { A BC D } , F = { A B → C , BC → D , C D → A , A D → B }
本身就满足BCNF
四 R ( U , F ) : U = { A B C D E } , F = { A B → C , D E → C , B → D } R(U,F):U=\{ABCDE\},F=\{AB \rightarrow C,DE\rightarrow C,B\rightarrow D\} R ( U , F ) : U = { A BC D E } , F = { A B → C , D E → C , B → D }
三个函数依赖都不满足BCNF,首先分解为 R 1 ( A B C ) , R 2 ( A B D E ) R_1(ABC),R_2(ABDE) R 1 ( A BC ) , R 2 ( A B D E ) R 2 R_2 R 2 R 21 ( B D ) , R 22 ( A B E ) R_{21}(BD),R_{22}(ABE) R 21 ( B D ) , R 22 ( A BE )
五 R ( U , F ) : U = { A B C D E F } , F = { A → B , C → D F , A C → E , D → F } R(U,F):U=\{ABCDEF\},F=\{A \rightarrow B,C\rightarrow DF,AC\rightarrow E,D\rightarrow F\} R ( U , F ) : U = { A BC D EF } , F = { A → B , C → D F , A C → E , D → F }
除了 A C → E AC \rightarrow E A C → E A → B A \rightarrow B A → B R 1 ( A B ) , R 2 ( A C D E F ) R_1(AB),R_2(ACDEF) R 1 ( A B ) , R 2 ( A C D EF ) C → D F C\rightarrow DF C → D F R 21 ( C D F ) , R 22 ( A C E ) R_{21}(CDF),R_{22}(ACE) R 21 ( C D F ) , R 22 ( A CE ) D → F D\rightarrow F D → F R 21 R_{21} R 21 R 211 ( D F ) , R 212 ( C D ) R_{211}(DF),R_{212}(CD) R 211 ( D F ) , R 212 ( C D )
分解为3NF 一 R ( U , F ) : U = { A B C D } , F = { A B → C , C → D , D → A } R(U,F):U=\{ABCD\},F=\{AB \rightarrow C,C\rightarrow D,D\rightarrow A\} R ( U , F ) : U = { A BC D } , F = { A B → C , C → D , D → A }
候选码不唯一,有 A B , B C , B D AB,BC,BD A B , BC , B D A , C , D A,C,D A , C , D
二 R ( U , F ) : U = { A B C D } , F = { B → C , B → D } R(U,F):U=\{ABCD\},F=\{B \rightarrow C,B\rightarrow D\} R ( U , F ) : U = { A BC D } , F = { B → C , B → D }
候选码是 A B AB A B B B B C 、 D C、D C 、 D F c = { B → C D } F_c=\{B\rightarrow CD\} F c = { B → C D } ( { B C D } , { A B } ) (\{BCD\},\{AB\}) ({ BC D } , { A B })
三 R ( U , F ) : U = { A B C D } , F = { A B → C , B C → D , C D → A , A D → B } R(U,F):U=\{ABCD\},F=\{AB \rightarrow C,BC\rightarrow D,CD\rightarrow A,AD \rightarrow B\} R ( U , F ) : U = { A BC D } , F = { A B → C , BC → D , C D → A , A D → B }
属于3NF。
四 R ( U , F ) : U = { A B C D E } , F = { A B → C , D E → C , B → D } R(U,F):U=\{ABCDE\},F=\{AB \rightarrow C,DE\rightarrow C,B\rightarrow D\} R ( U , F ) : U = { A BC D E } , F = { A B → C , D E → C , B → D }
候选码为 A B E ABE A BE F c = F F_c=F F c = F ( { A B C } , { D E C } , { B D } , { A B E } ) (\{ABC\},\{DEC\},\{BD\},\{ABE\}) ({ A BC } , { D EC } , { B D } , { A BE })
五 R ( U , F ) : U = { A B C D E F } , F = { A → B , C → D F , A C → E , D → F } R(U,F):U=\{ABCDEF\},F=\{A \rightarrow B,C\rightarrow DF,AC\rightarrow E,D\rightarrow F\} R ( U , F ) : U = { A BC D EF } , F = { A → B , C → D F , A C → E , D → F }
候选码为 A C AC A C F c = { A → B , C → D , A C → E , D → F } F_c=\{A \rightarrow B,C\rightarrow D,AC\rightarrow E,D\rightarrow F\} F c = { A → B , C → D , A C → E , D → F } ( { A B } , { C D } , { A C E } , { D F } ) (\{AB\},\{CD\},\{ACE\},\{DF\}) ({ A B } , { C D } , { A CE } , { D F })
作业题拾遗 R ( { A , B , C , D , E , G } , { A → B C D , B C → D E , B → D , D → A } ) R(\{A,B,C,D,E,G\},\{A \rightarrow BCD,BC\rightarrow DE,B\rightarrow D,D\rightarrow A\}) R ({ A , B , C , D , E , G } , { A → BC D , BC → D E , B → D , D → A })
计算 F c F_c F c
由 B → D B\rightarrow D B → D F 1 = { A → B C , B C → E , B → D , D → A } F_1=\{A\rightarrow BC,BC\rightarrow E,B\rightarrow D,D\rightarrow A\} F 1 = { A → BC , BC → E , B → D , D → A }
由 B → D , D → A , A → B C B\rightarrow D,D\rightarrow A,A\rightarrow BC B → D , D → A , A → BC B → C B\rightarrow C B → C F 2 = { A → B C , B → E , B → D , D → A } F_2=\{A\rightarrow BC,B\rightarrow E,B\rightarrow D,D\rightarrow A\} F 2 = { A → BC , B → E , B → D , D → A }
注意这种多级传递的情况,可能遗漏 注意一次只处理一个函数依赖 合并相同左项得 F c = { A → B C , B → D E , D → A } F_c=\{A\rightarrow BC,B\rightarrow DE,D\rightarrow A\} F c = { A → BC , B → D E , D → A }